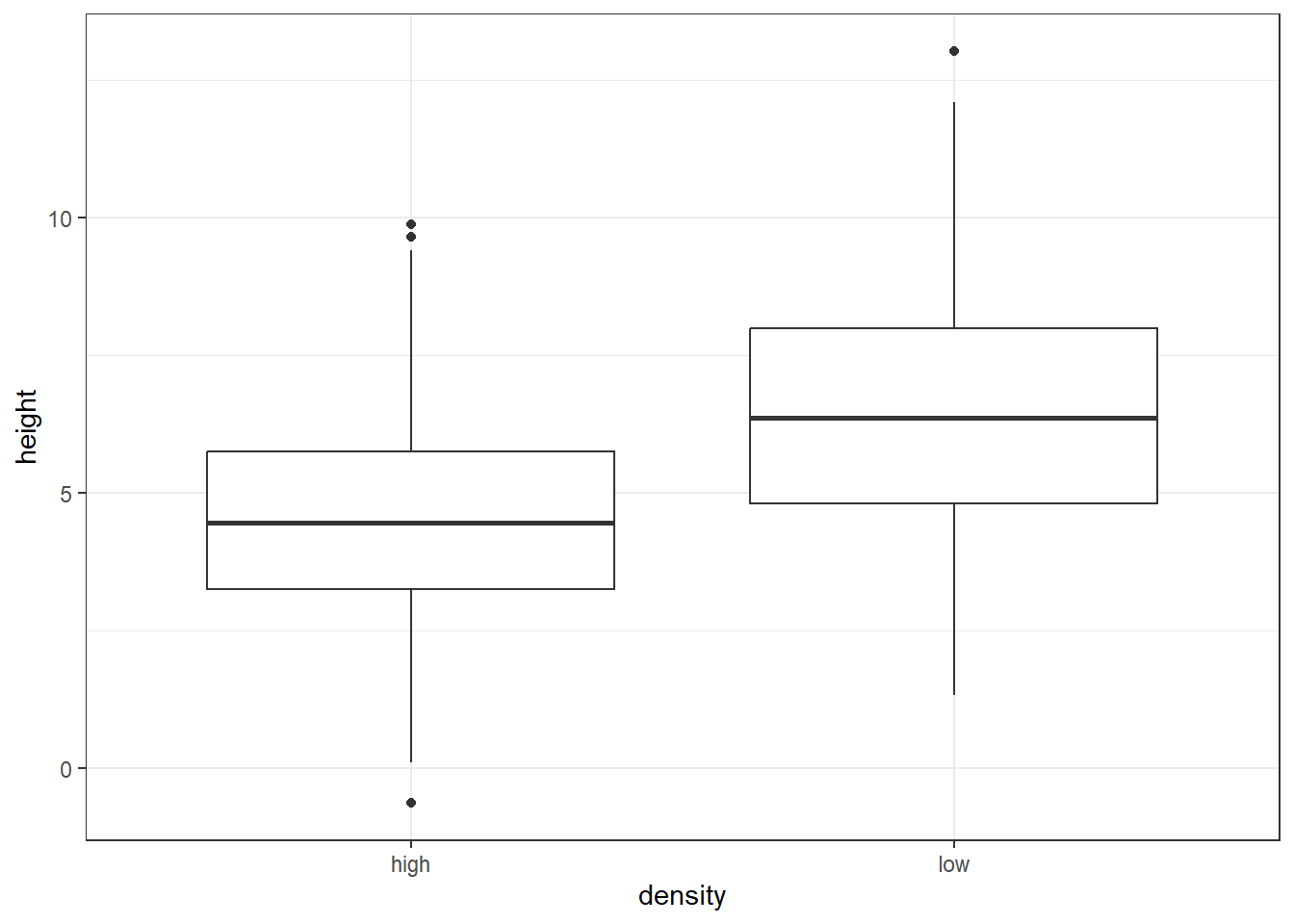Explore non-parametric alternatives to the t-test.
2 Start a Script
For this lab or project, begin by:
Starting a new R script
Create a good header section and table of contents
Save the script file with an informative name
set your working directory
Aim to make the script a future reference for doing things in R!
3 t-tests
The typical premise of the t-test is that it is used to compare populations you are interested in, which you measure with independent samples.1 There are a few versions of the basic question:
One-sample t-test - compare the mean of a sample to a known value;
Two-sample t-test - compare the means of two independent samples;
Paired t-test - compare the means of two paired samples.
4 One-Sample t-test
The one-sample t-test is a simple statistical test used when we have a sample of a numeric variable and want to compare its population mean to a particular value. The one-sample t-test evaluates whether the population mean is likely to be different from this value. The expected value could be any value we are interested in.
4.1 How does the one-sample t-test work?
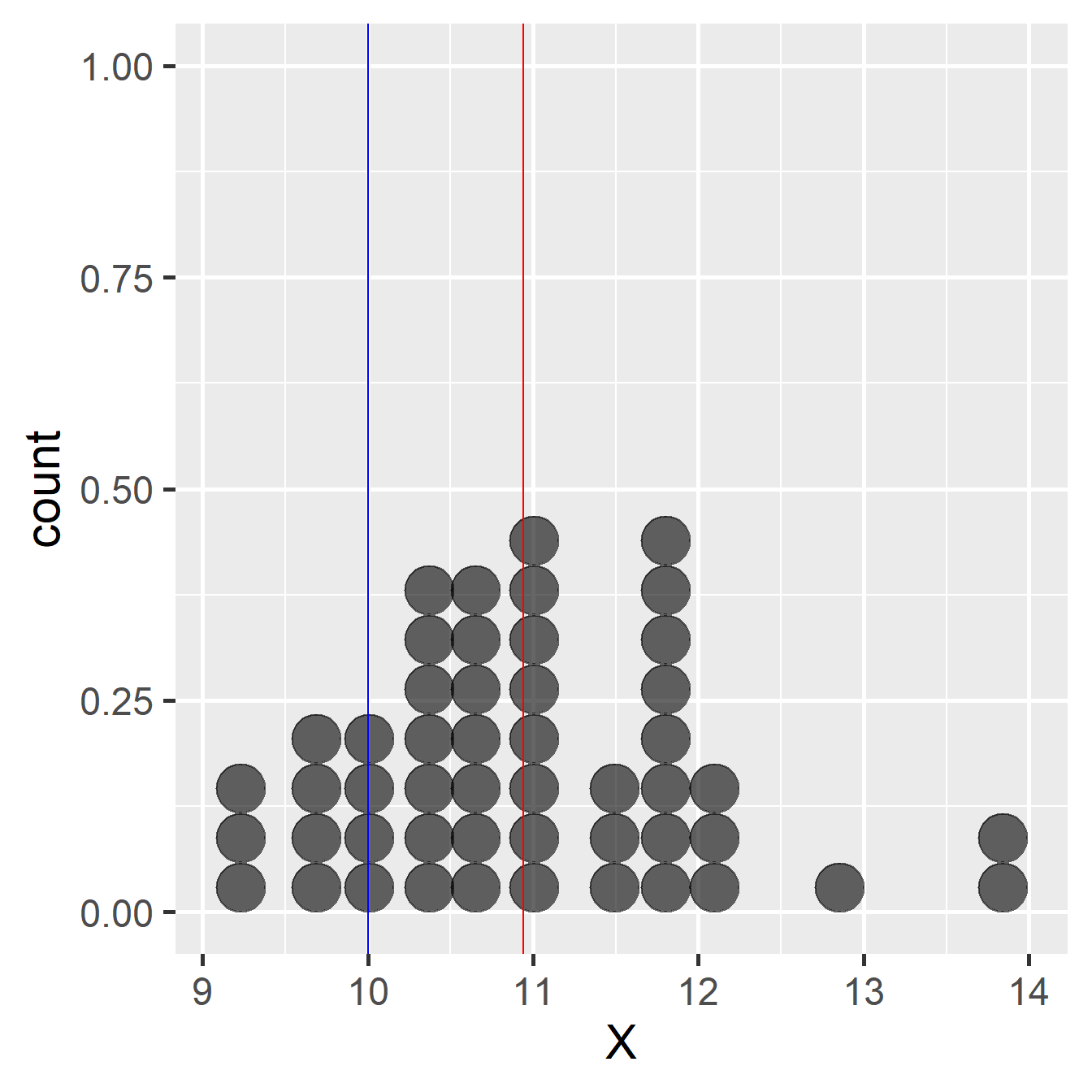
Imagine we have taken a sample of some variable and we want to evaluate whether its mean is different from some number (the ‘expected value’ or statistically known as mu). Here’s an example of what these data might look like if we had used a sample size of 50:
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.0
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Example of data used in a one-sample t-test
We’re calling the variable X in this example. The red line shows the sample mean. This is a bit less than 11. The blue line shows the expected value of 10. The observed sample mean is about one unit larger than the expected value. The question is, how do we decide whether the population mean is really different from the expected value? Perhaps the difference between the observed and expected value is due to sampling variation. Here’s how we can tackle this kind of question:
Set up an appropriate null hypothesis, i.e., an hypothesis of ‘no effect’ or ‘no difference’. The null hypothesis in this type of question is that the population mean is equal to the expected value.
Work out what the sampling distribution of a sample mean looks like under the null hypothesis. This is the null distribution. Because we’re now using a parametric approach, we will assume this has a particular form.
Finally, we use the null distribution to assess how likely the observed result is under the null hypothesis. This is the p-value calculation that we use to summarise our test.
We can use this knowledge to construct the test of statistical significance. We only need three simple pieces of information to construct the test: sample size, sample variance and sample mean. The one-sample t-test is then carried out as follows:
Step 1. Calculate the sample mean. This happens to be our ‘best guess’ of the unknown population mean. However, its role in the one-sample t-test is to allow us to construct a test statistic in the next step.
Step 2. Estimate the standard error of the sample mean. This gives us an idea of how much sampling variation we expect to observe. The standard error doesn’t depend on the true value of the mean, so the standard error of the sample mean is also the standard error of any mean under any particular null hypothesis.
This second step boils down to applying a simple formula involving the sample size and the standard deviation of the sample:
\[\text{Standard Error of the Mean} = \sqrt{\frac{s^2}{n}}\]
…where \(s^2\) is the square of the standard deviation (the sample variance) and \(n\) is for the sample size. The standard error of the mean gets smaller as the sample sizes grows or the sample variance shrinks.
Step 3. Calculate a ‘test statistic’ from the sample mean and standard error. We calculate this by dividing the sample mean (step 1) by its estimated standard error (step 2):
\[\text{t} = \frac{\text{Sample Mean}}{\text{Standard Error of the Mean}}\]
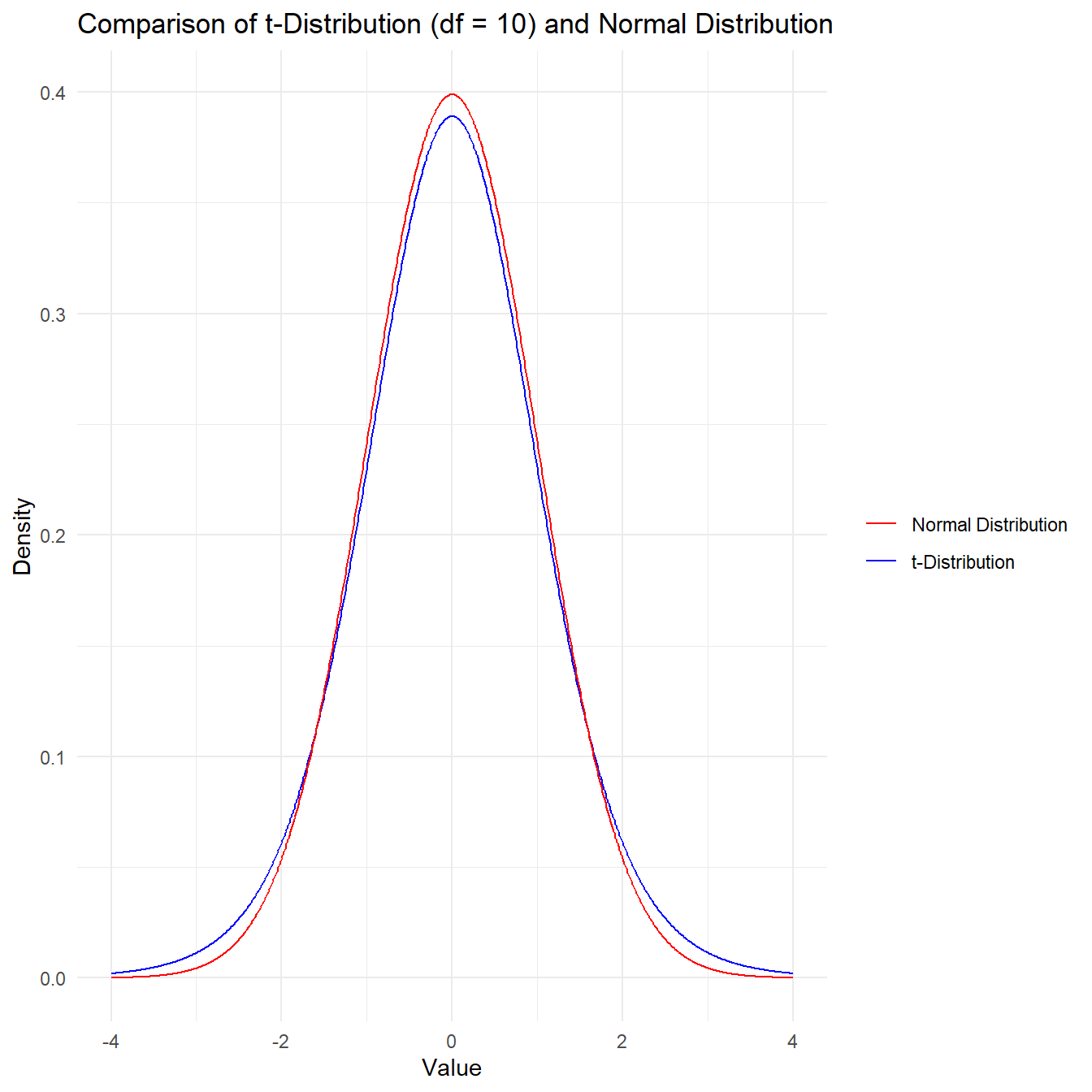
If our normality assumption is reasonable this test-statistic follows a t-distribution. This is guaranteed by the normality assumption. So this particular test statistic is also a t-statistic. That’s why we label it t.
Comparison of a normal distribution and t-distribution
The t-distribution is similar to the normal distribution, but has heavier tails. The shape of the t-distribution depends on the sample size. The larger the sample size, the more similar the t-distribution is to the normal distribution. The t-distribution is also ‘centred’ on zero, like the normal distribution. The ‘degrees of freedom’ parameter of the t-distribution controls the shape of the distribution. The degrees of freedom for the one-sample t-test is equal to the sample size minus one. So, for example, if we have a sample size of 50, the degrees of freedom is 49. The larger the degrees of freedom, the more similar the t-distribution is to the normal distribution. This knowledge leads to the final step…
Step 4. Compare the t-statistic to the theoretical predictions of the t-distribution to assess the statistical significance of the difference between observed and expected value. We calculate the probability that we would have observed a difference with a magnitude as large as, or larger than, the observed difference, if the null hypothesis were true. That’s the p-value for the test.
We could step through the actual calculations involved in these steps in detail, using R to help us, but there’s no need to do this. We can let R handle everything for us. But first, we should review the assumptions of the one-sample t-test.
4.2 Assumptions of the one-sample t-test
There are a number of assumptions that need to be met in order for a one-sample t-test to be valid. Some of these are more important than others. We’ll start with the most important and work down the list in reverse order of importance:
Independence: In rough terms, independence means each observation in the sample does not ‘depend on’ the others.
Measurement scale: The variable being analysed should be measured on an interval or ratio scale, i.e. it should be a numeric variable of some kind. It doesn’t make much sense to apply a one-sample t-test to a variable that isn’t measured on one of these scales.
Normality: The one-sample t-test will only produce completely reliable p-values when the variable is normally distributed in the population. However, this assumption is less important than many people think. The t-test is robust to mild departures from normality when the sample size is small, and when the sample size is large the normality assumption hardly matters at all.
4.3 Evaluating the assumptions
The first two assumptions—independence and measurement scale—are really aspects of experimental design. We can only evaluate these by thinking carefully about how the data were gathered and what was measured. It’s too late to do anything about these after we have collected our data.
What about that 3rd assumption—normality? One way to evaluate this is by visualising the sample distribution. For small samples, if the sample distribution looks approximately normal then it’s probably fine to use the t-test. For large samples, we don’t even need to worry about a moderate departures from normality.
4.4 The one-sample t-test in R
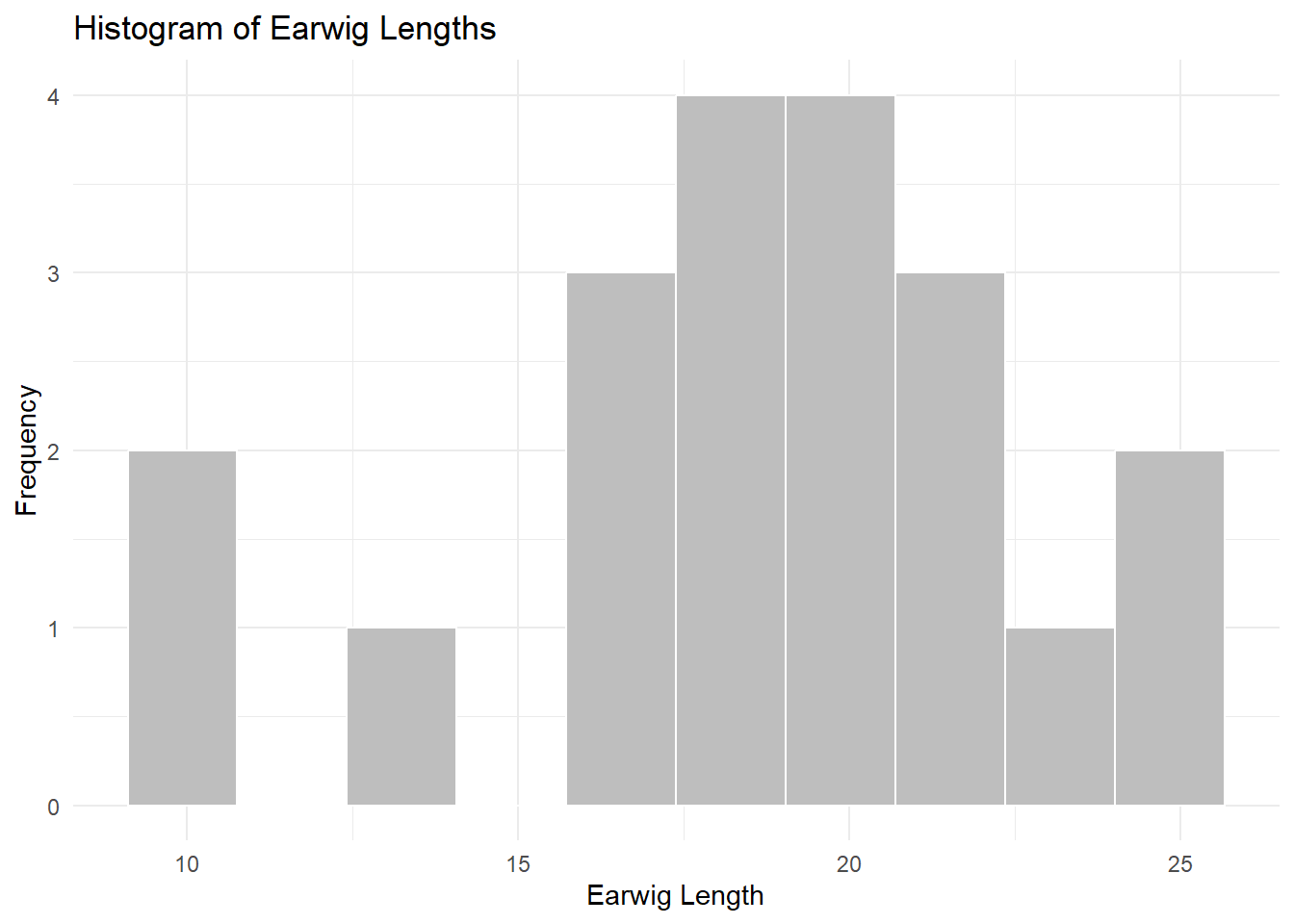
This example is a sample of earwigs measured in length to the nearest 0.1 mm. There is a hypothesis that global warming has impacted the development in the population and they are getting larger. A long term data set has established a mean earwig length of 17.0 (NB, this is our estimate of “mu” or the population mean we will compare our sample to). Are the earwigs getting bigger? We can use a one-sample t-test to test this hypothesis. First let’s assess this data for adherence to the assumptions of the t-test.
# Dataearwigs <-c(22.1, 16.3, 19.1, 19.9, 19.2, 17.7, 22.5, 17.7, 24.1, 17.8, 21.9, 24.9, 13.8, 17.2, 17.6, 19.9, 17.1, 10, 10.7, 22)# Assuming 'earwigs' is a numeric vector, convert it to a data frameearwigs_data <-data.frame(value = earwigs)# Create the histogram using ggplot2ggplot(earwigs_data, aes(x = value)) +geom_histogram(bins =10, fill ="grey", color ="white") +theme_minimal() +xlab("Earwig Length") +ylab("Frequency") +ggtitle("Histogram of Earwig Lengths")
It isn’t perfect, but probably good enough. We can also use the Shapiro-Wilk test to formally test for normality. This test is available in R as shapiro.test(). The null hypothesis of this test is that the data are normally distributed. The alternative hypothesis is that the data are not normally distributed. Let’s run the test:
# Test for normalityshapiro.test(earwigs)
Shapiro-Wilk normality test
data: earwigs
W = 0.94481, p-value = 0.2951
The p-value is 0.295, which is not significant at the 5% level. So we can’t reject the null hypothesis that the data are normally distributed. This is good news because it means we can use the t-test. Now we can carry out the test using the t.test() function in R. This function takes two arguments: the first is the data, and the second is the expected value. In this case, the expected value is the population mean, which is 17.0. So we run the test like this:
# One-sample t-testt.test(earwigs, # A numeric vector containing the sample valuesmu =17) # The population mean we are comparing to
One Sample t-test
data: earwigs
t = 1.7845, df = 19, p-value = 0.09031
alternative hypothesis: true mean is not equal to 17
95 percent confidence interval:
16.72775 20.42225
sample estimates:
mean of x
18.575
The first line tells us what kind of t-test we used. This says: One Sample t-test. OK, now we know that we used the one-sample t-test. The next line reminds us about the data. This says: data: earwigs, which is R-speak for ’we compared the mean of the Weight variable to an expected value. Which value? This is given later.
The third line of text is the most important. This says: t = 1.7845, df = 19, p-value = 0.09031. The first part of this, t = 1.7845, is the test statistic, i.e., the value of the t-statistic. The second part, df = 19, summarise the ‘degrees of freedom’. This is required to work out the p-value. It also tells us something about how much ‘power’ our statistical test has (see the box below). The third part, *p*-value = 0.09031, is the all-important p-value.
That p-value indicates that there is no statistically significant difference between the earwig length and the expected value of 17 mm (p is more than 0.05).
The fourth line of text (alternative hypothesis: true mean is not equal to 17) tells us what the alternative to the null hypothesis is (H1). More importantly, this serves to remind us which expected value was used to formulate the null hypothesis (mean = 17).
The next two lines show us the ‘95% confidence interval’ for the difference between the means. We don’t really need this information now, but we can think of this interval as a rough summary of the likely values of the ‘true’ mean4.
The last few lines summarise the sample mean. This might be useful if we had not already calculated.
4.5 Visualising the data
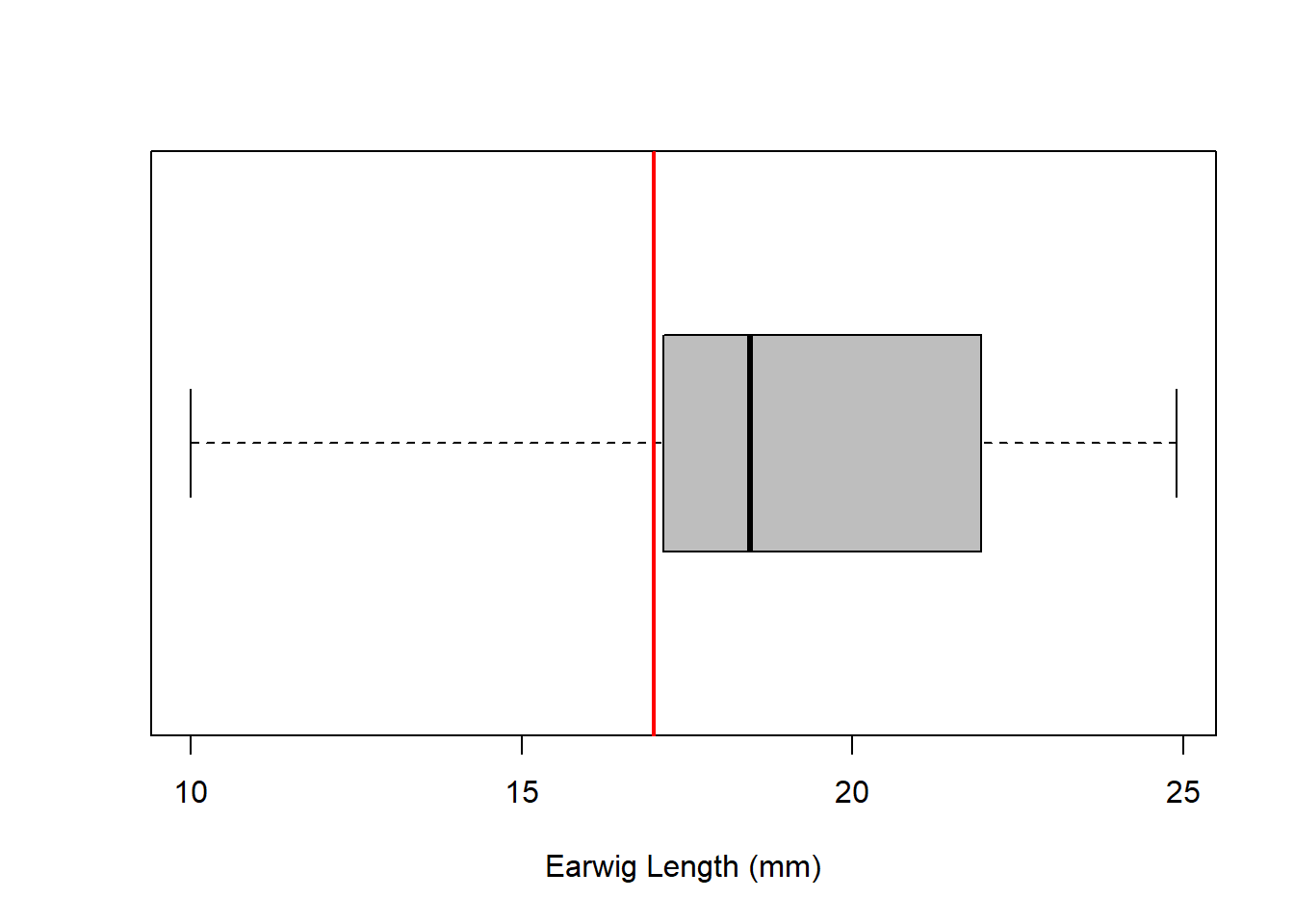
The p-value is the most important part of the output, but it is also useful to visualise the result. We can do this by plotting the sample distribution and the expected value on the same graph, which is usually a boxplot. We can also add a vertical line to indicate the mean of the sample.
# Plot the databoxplot(earwigs, horizontal =TRUE, col ="grey", xlab ="Earwig Length (mm)")# Add a vertical line to indicate the expected valueabline(v =17, col ="red", lwd =2)
4.6 Summarising the result
Having obtained the result we now need to write our conclusion. We are testing a scientific hypothesis, so we must always return to the original question to write the conclusion. In this case the appropriate conclusion is:
There was no statistically significant difference between the mean length of the earwigs and the expected value of 17 mm (t = 1.78, df = 19, p = 0.09).
This is a concise and unambiguous statement in response to our initial question. The statement indicates not just the result of the statistical test, but also which value was used in the comparison.
Notice that we include details of the test in the conclusion. However, keep in mind that when writing scientific reports, the end result of any statistical test should be a conclusion like the one above. Simply writing t = 3.18 or p < 0.01 is not an adequate conclusion.
There are a number of common questions that arise when presenting t-test results:
What do I do if t is negative? Don’t worry. A t-statistic can come out negative or positive, it simply depends on which order the two samples are entered into the analysis. Since it is just the absolute value of t that determines the p-value, when presenting the results, just ignore the minus sign and always give t as a positive number.
How many significant figures for t? The t-statistic is conventionally given to 3 significant figures. This is because, in terms of the p-value generated, there is almost no difference between, say, t = 3.1811 and t = 3.18.
Upper or lower case The t statistic should always be written as lower case when writing it in a report (as in the conclusions above). Similarly, d.f. and p are always best as lower case. Some statistics we encounter later are written in upper case but, even with these, d.f. and p should be lower case.
5 Two-Sample t-test
The two-sample t-test can be used to compare the means of a numeric variable sampled from two independent populations. The question here is: are the means of the two samples different (i.e., did the samples come from different populations)? A typical design here might be an experiment with a control and one treatment group. For example, we might want to know if the mean length of earwigs is different in two different habitats. We might sample earwigs from two different habitats and compare the mean length of the two samples.
5.1 How does the two-sample t-test work?
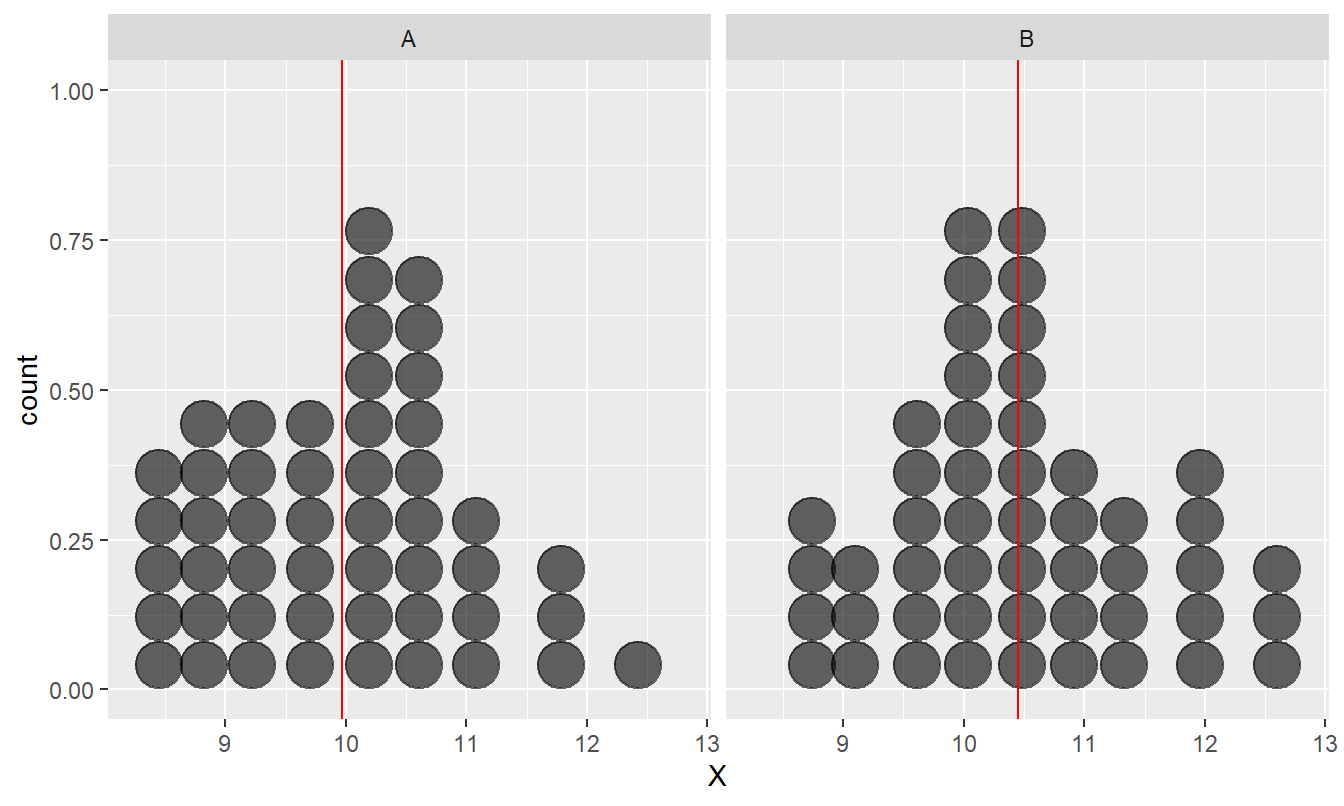
Imagine we have taken a sample of a variable from two populations, labelled ‘A’ and ‘B’. We’ll call the variable ‘X’ again. Here’s an example of how these kinds of data might look if we had a sample of 50 items from each population:
Example of data used in a two-sample t-test
The first thing to notice is the two distributions overlap quite a lot. However, this observation isn’t necessarily all that significant. Why? Because we’re not interested in the raw values of X in the two samples. It’s the difference between the means that our test is going to focus on.
The red lines show the mean of each sample. Sample B obviously has a larger mean than sample A. The question is, how do we decide whether this difference is ‘real’, or purely a result of sampling variation? We tackle this question by first setting up the appropriate null hypothesis. The null hypothesis here is one of no difference between the population means (they are equal). We then have to work out what the null distribution looks like. This is sampling distribution of the difference between sample means under the null hypothesis. Once we have the null distribution worked out we can calculate a p-value. We only need a few pieces of information to carry out a two-sample t-test. These are basically the same quantities needed to construct the one-sample t-test, except now there are two samples involved: sample sizes of groups A and B, the sample variances and the estimated difference between the sample means of X in A and B.
How does two-sample t-test actually work? It is carried out as follows:
Step 1. Calculate the two sample means then calculate the difference between these estimates. This estimate is our ‘best guess’ of the true difference between means. As with the one-sample test, its role in the two-sample t-test is to allow us to construct a test statistic.
Step 2. Estimate the standard error of the difference between the sample means under the null hypothesis of no difference. This gives us an idea of how much sampling variation we expect to observe in the estimated difference, if there were actually no difference between the means.
There are a number of different options for estimating this standard error. Each one makes a different assumption about the variability of the two populations. Which ever choice we make the calculation always boils down to a simple formula involving the sample sizes and sample variances. The standard error gets smaller when the sample sizes grow, or when the sample variances shrink. That’s the only important point, really.
Step 3. Once we have estimated the difference between sample means and its standard error, we can calculate the test statistic. This is a type of t-statistic, which we calculate by dividing the difference between sample means (from step 1) by the estimated standard error of the difference (from step 2):
\[\text{t} = \frac{\text{Difference Between Sample Means}}{\text{Standard Error of the Difference}}\]
This t-statistic is guaranteed to follow a t-distribution if the normality assumption is met. This knowledge leads to the final step…
Step 4. Compare the test statistic to the theoretical predictions of the t-distribution to assess the statistical significance of the observed difference. That is, we calculate the probability that we would have observed a difference between means with a magnitude as large as, or larger than, the observed difference, if the null hypothesis were true. That’s the p-value for the test.
We will not step through the various calculations involved in these steps because we’re going to let R to handle the calculations for us. Let’s review the assumptions of the two-sample t-test first…
5.2 Assumptions of the two-sample t-test
Several assumptions need to be met for a two-sample t-test to be valid. These are basically the same as those for the one-sample version. Starting with the most important and working down in decreasing order of importance, these are:
Independence: Remember what we said in our discussion of the one-sample t-test? If the data are not independent, the p-values generated by the test will be too small, and even mild non-independence can be a serious problem. The same is true of the two-sample t-test.
Measurement scale: The variable we are working with should be measured on an interval or ratio scale, which means it will be numeric. It makes little sense to apply a two-sample t-test to a categorical variable of some kind.
Normality: The two-sample t-test will produce reliable p-values if the variable is normally distributed in each population. However, the two-sample t-test is fairly robust to mild departures from normality and this assumption matters little when the sample sizes are large.
5.3 Evaluating the assumptions
How do we evaluate the first two assumptions? As with the one-sample test, these are aspects of experimental design—we can only evaluate them by thinking about the data we’ve collected.
The normality assumption can be evaluated by plotting the the sample distribution of each group using, for example, a pair of histograms or dot plots. We must examine the distribution in each group, not the distribution of the combined sample. If both samples looks approximately normal then we can proceed with the test. If we think we can see a departure from normality then we should consider our sample sizes before deciding to proceed, remembering that the test is robust to mild departures when sample sizes are large (e.g. >100 observations in each group).
What about the equal variance assumption?
It is sometimes said that a two-sample t-test requires the variability (‘variance’) of each sample to be the same, or at least quite similar. This would be true if we used the original version of Student’s two-sample t-test. However, R doesn’t use this version of the test by default. R uses the “Welch” two-sample t-test. This version of the test does not rely on the equal variance assumption. As long as we stick with this version of the t-test, the equal variance assumption isn’t something we need to worry about.
5.4 The two-sample t-test in R
The example we will use here is the amount of tree growth over a period of time, where samples were taken of individual trees grown under two conditions - high density of trees versus low density. The hypothesis we are testing is whether there is evidence the samples came from different populations (by inference, we are possibly interested in whether there is an effect of density on growth).
We start by calculating a few descriptive statistics and visualising the sample distributions of the high and low density heights:
# Descriptive statisticstreegrowth %>%# group the data by plant morphgroup_by(density) %>%# calculate the mean, standard deviation and sample sizesummarise(mean =mean(height), sd =sd(height),samp_size =n())
# A tibble: 2 × 4
density mean sd samp_size
<chr> <dbl> <dbl> <int>
1 high 4.51 2.11 140
2 low 6.44 2.30 140
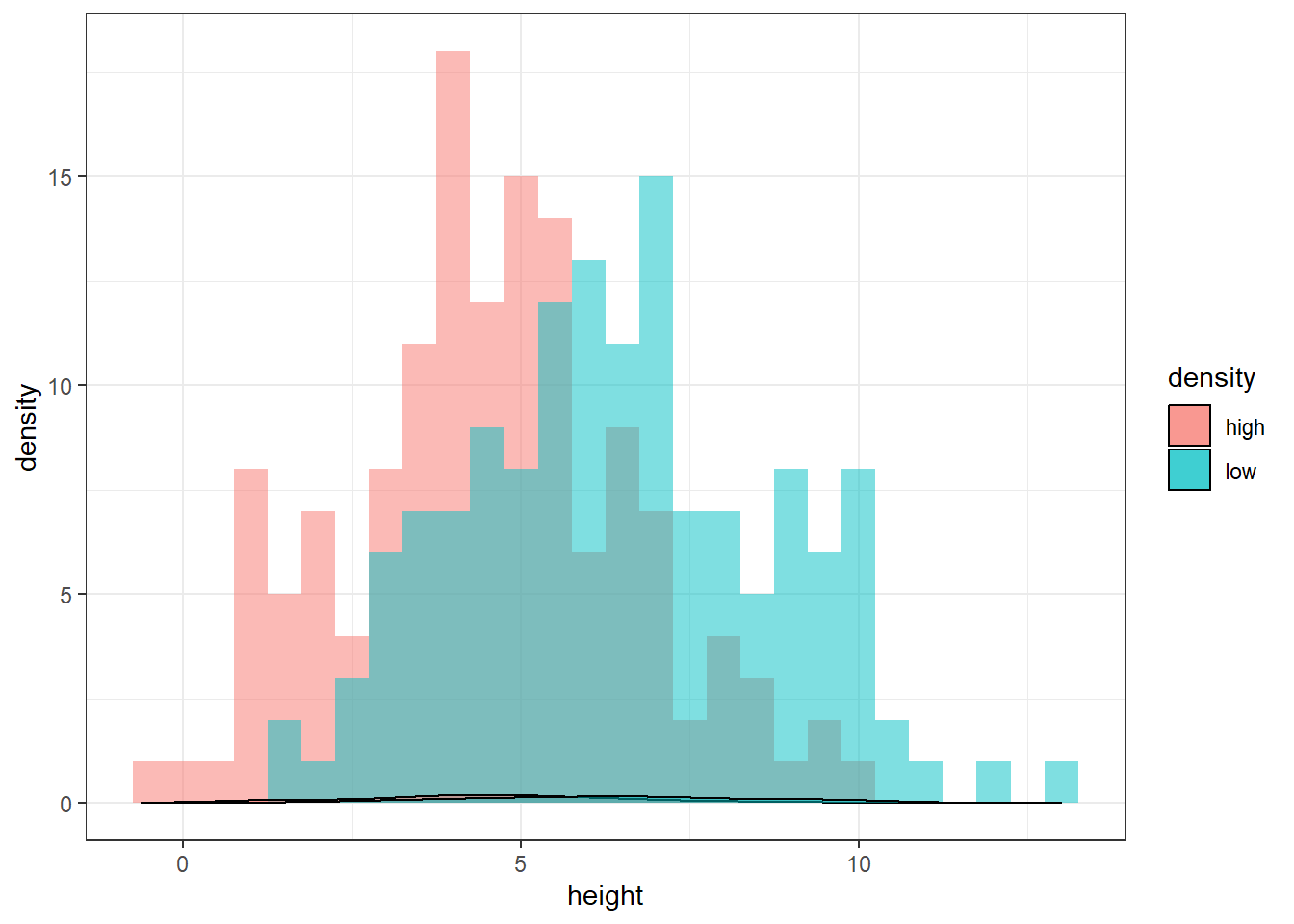
Based on this summary, it looks like the mean height of the low density group is slightly higher than the high density group. We can visualise the distributions of the two groups using a pair of histograms:
# Visualise the distributionstreegrowth %>%ggplot(aes(x = height, fill = density)) +geom_histogram(binwidth =0.5, alpha =0.5, position ="identity") +geom_density(alpha =0.5) +theme_bw()
The distributions look approximately normal, and the sample sizes are large, so we can proceed with the test. We will use the t.test() function in R to perform the test. The function takes two arguments: the first is a formula specifying the variable we want to test and the grouping variable, and the second is the name of the data frame containing the data. The grouping variable is specified using the ~ symbol, and the variable we want to test is specified on the left hand side of the ~ symbol. The grouping variable is specified on the right hand side of the ~ symbol. The grouping variable must be a factor variable.
# Perform the testt.test(height ~ density, data = treegrowth)
Welch Two Sample t-test
data: height by density
t = -7.3349, df = 276.04, p-value = 2.475e-12
alternative hypothesis: true difference in means between group high and group low is not equal to 0
95 percent confidence interval:
-2.451837 -1.414237
sample estimates:
mean in group high mean in group low
4.508604 6.441641
The first line reminds us what kind of t-test we used. This says: Welch two-sample t-test, so we know that we used the Welch version of the test that accounts for the possibility of unequal variance. The next line reminds us about the data. This says: data: height by density, which is R-speak for ‘we compared the means of the height variable, where the group membership is defined by the values of the density variable’.
The third line of text is the most important. This says: t = -8.6817, df = 276.9, p-value = 3.42e-16. The first part, t = -8.6817, is the test statistic (i.e. the value of the t-statistic). The second part, df = 276.9, summarise the ‘degrees of freedom’. The third part, p-value = 3.42e-16, is the all-important p-value. This says there is a statistically significant difference in the mean tree height of the densities, because p<0.05. Because the p-value is less than 0.001 we would report this as ‘p < 0.01’.
The fourth line of text (alternative hypothesis: true difference in means is not equal to 0) simply reminds us of the alternative to the null hypothesis (H1). This isn’t hugely important or interesting.
The next two lines show us the ‘95% confidence interval’ for the difference between the means. Just as with the one sample t-test we can think of this interval as a rough summary of the likely values of the true difference (again, a confidence interval is more complicated than that in reality).
The last few lines summarise the sample means of each group. This could be useful if we had not bothered to calculate these already.
5.5 Visulising the data
We can visualise the data in a few different ways. First, we can plot the data as a boxplot:
# Visualise the data as a boxplottreegrowth %>%ggplot(aes(x = density, y = height)) +geom_boxplot() +theme_bw()
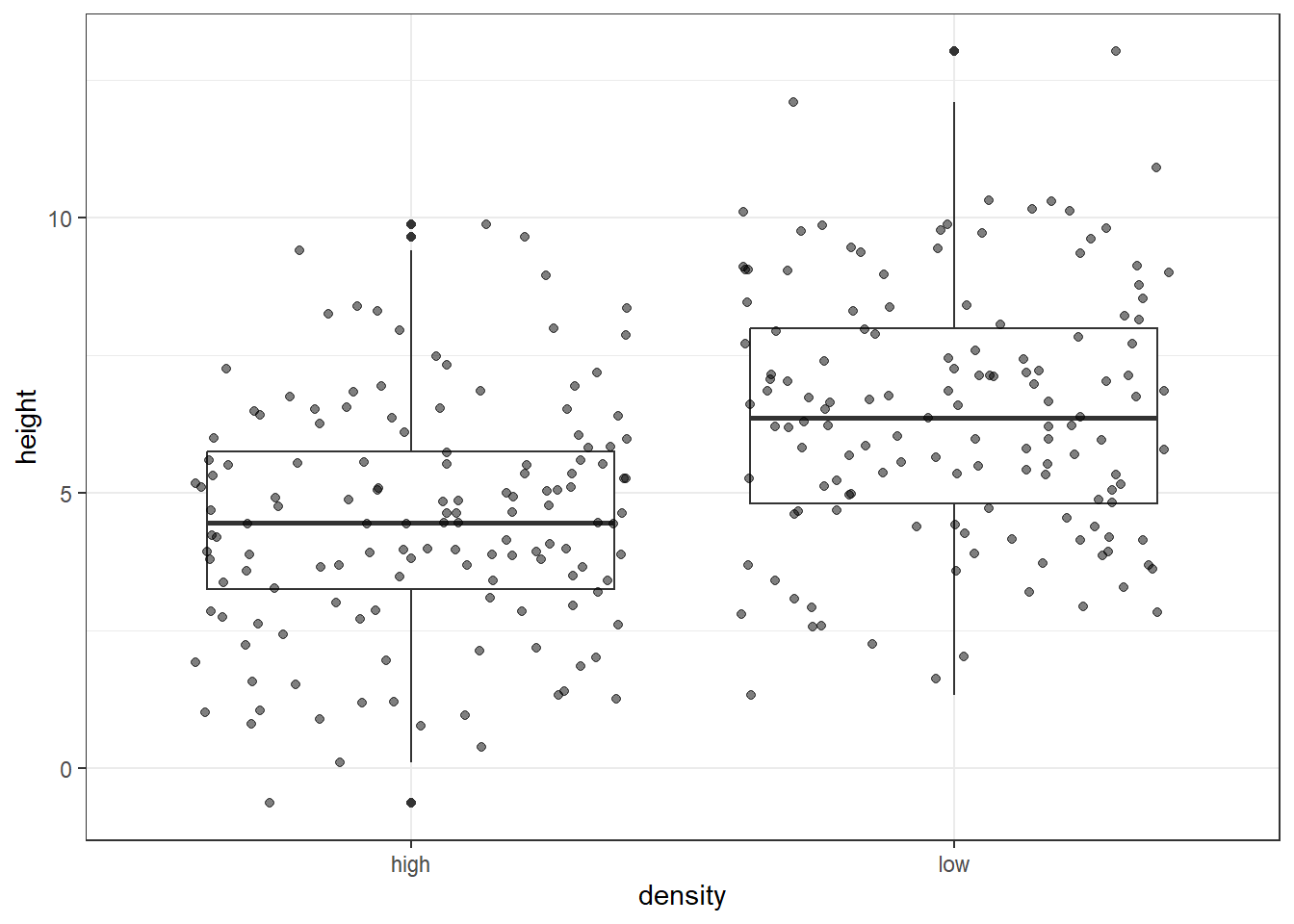
This shows us the median and interquartile range of each group, as well as the minimum and maximum values. We can also add the individual data points to the plot:
# Visualise the data as a boxplot with individual data pointstreegrowth %>%ggplot(aes(x = density, y = height)) +geom_boxplot() +geom_jitter(alpha =0.5) +theme_bw()
5.6 Summarising the result
Having obtained the result we need to report it. We should go back to the original question to do this. In our example the appropriate summary is:
Mean height of high and low density trees differs significantly (Welch’s t = 8.68, d.f. = 276.9, p < 0.001), with low density trees being approximately 25 % taller.
This is a concise and unambiguous statement in response to our initial question. The statement indicates not just the result of the statistical test, but also which of the mean values is the larger. Always indicate which mean is the largest. It is sometimes appropriate to also give the values of the means:
The mean height of low density trees (6.7) is significantly greater than that of high density trees (4.1) (Welch’s t = 8.68, d.f. = 276.9, p < 0.001)
When we are writing scientific reports, the end result of any statistical test should be a statement like the one above—simply writing t = 8.68 or p < 0.001 is not an adequate conclusion!
6 Paired t-test
6.1 When do we use a paired t-test?
The paired t-test is used when we want to compare the means of two groups, but the data are paired. This means that each observation in one group is paired with an observation in the other group. For example, we might want to compare the measurement of some variable before and after a treatment (e.g. measure crop yield in plots in a field before and after a soil treatment in successive years). In this case, each plot is measured twice, once before and once after the treatment. The measurements are paired because they are both from the same plot.
An experimental design that sets out to produce paired-data is known as a paired-sample design. More often than not paired-sample data arise as consequence of such deliberate decisions. Why? In biology, we often have the problem that there is a great deal of variation between the units we’re studying (individual organisms, tissue samples, etc). There may be so much among-unit variation that the effect of any difference among the situations we’re really interested in is obscured. Using a paired-sample design gives us a way to control for the among-unit variation and increase the power of our statistical tests. However, we should not use a two-sample t-test when our data have this kind of structure. Let’s find out why.
6.2 Why do we need a paired t-test?
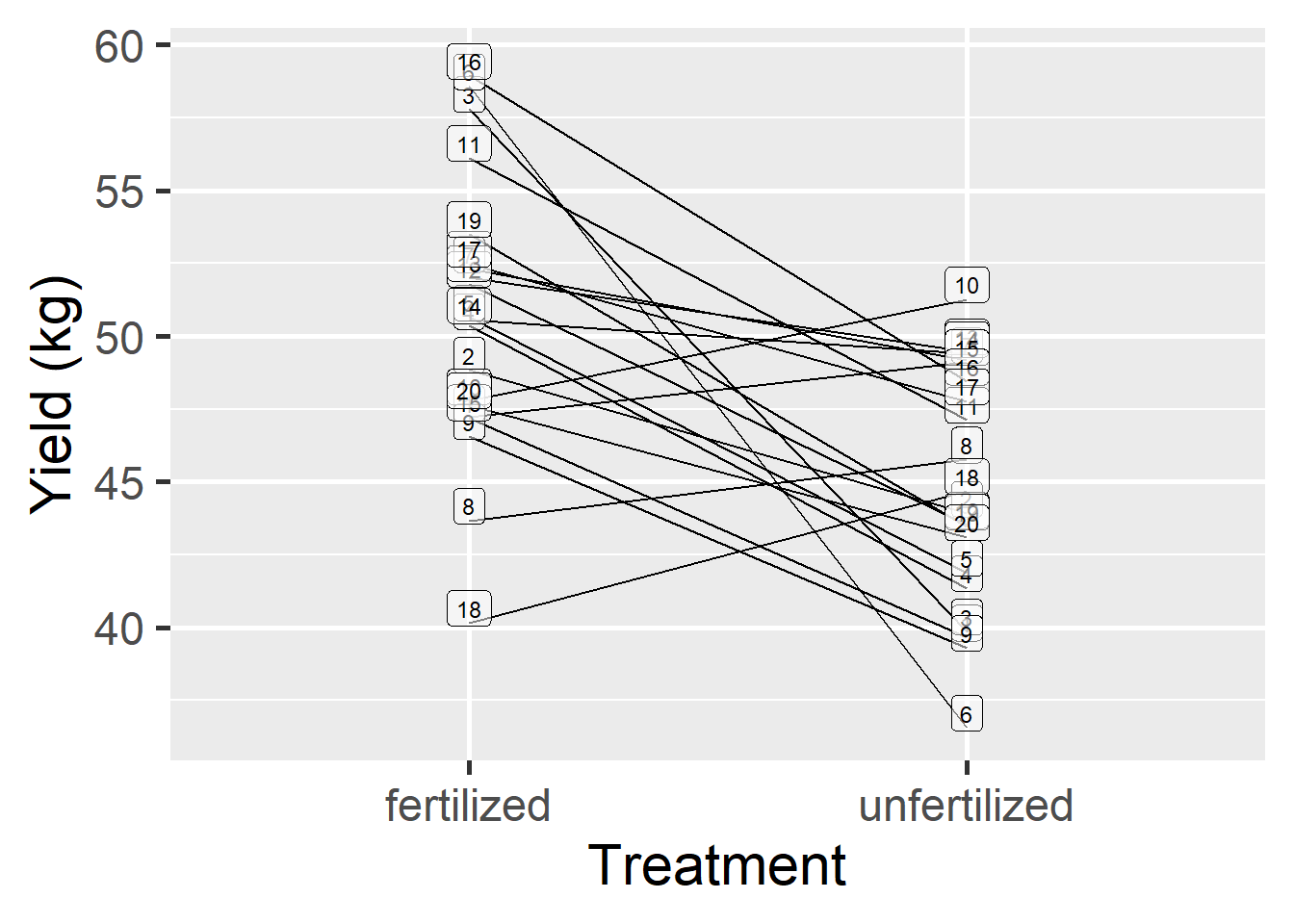
Imagine an agricultural research center conducting an experiment to test the effectiveness of a new organic fertilizer. The center has a field divided into 20 plots. Each plot is planted with the same crop variety. To assess the impact of the fertilizer, they decide to apply the new fertilizer to half of each plot and leave the other half as a control (without fertilizer).
The experiment is designed to compare the yield (in kilograms) from the fertilized half of each plot with the yield from the unfertilised half. This design allows the researchers to control for variability between different plots, as each plot serves as its own control.
The experimental design, and one hypothetical outcome, is represented in the diagram below…
Warning: package 'reshape2' was built under R version 4.3.2
How do we go about analysing paired data in a way that properly accounts for the structure in the data?
6.3 Assumptions
The assumptions of a paired-sample t-test are no different from the one-sample t-test. After all, they boil down to the same test! We just have to be aware of the target sample. The key point to keep in mind is that it is the sample of differences that is important, not the original data. There is no requirement for the original data to be drawn from a normal distribution because the normality assumption applies to the differences. This is very useful, because even where the original data seem to be drawn from a non-normal distribution, the differences between pairs can often be acceptably normal. The differences do need to be measured on an interval or ratio scale, but this is guaranteed if the original data are on one of these scales.
6.4 The paired t-test in R
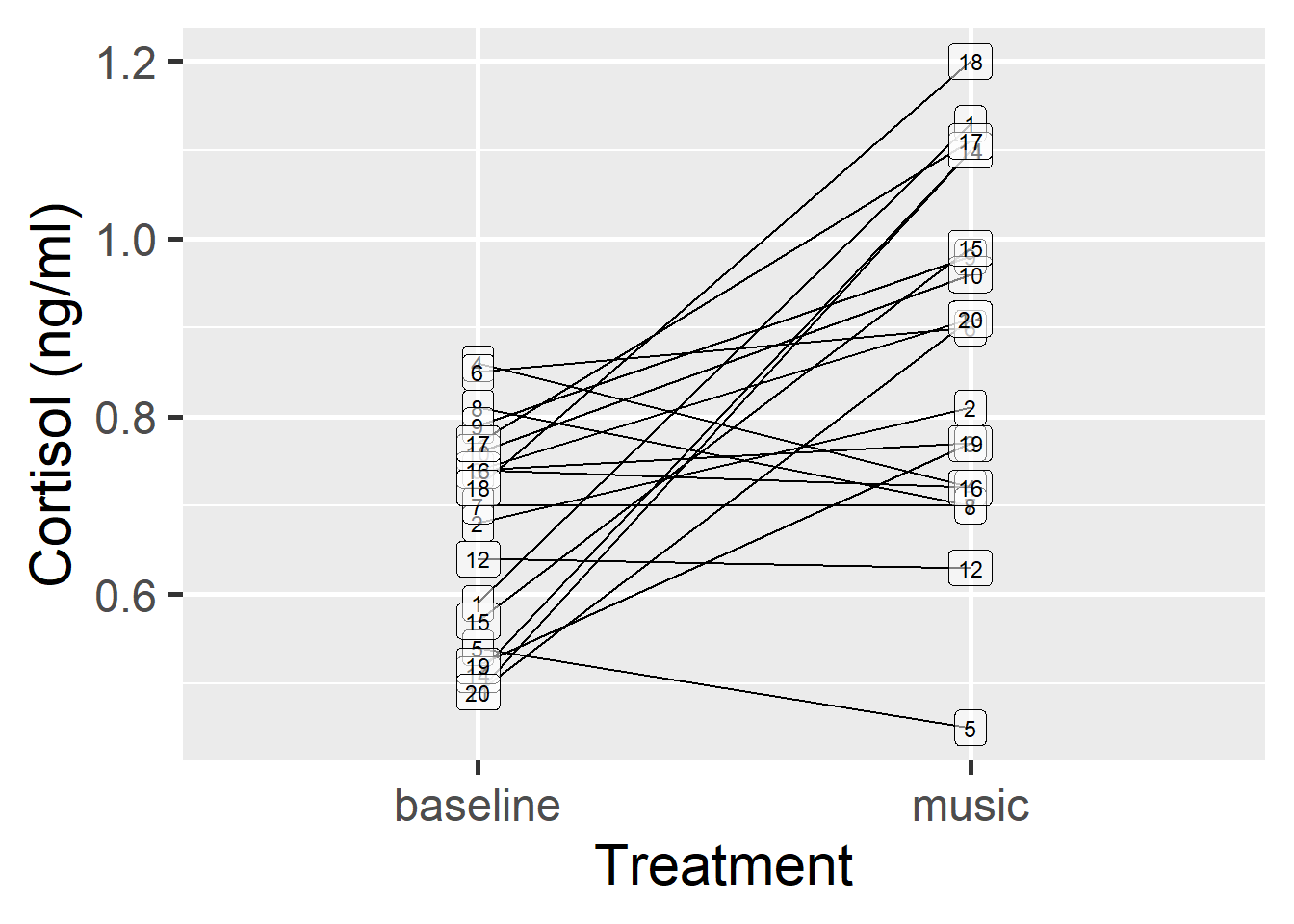
R offers the option of a paired-sample t-test to save us the effort of calculating differences. The example we will use here is a measure of the hormone cortisol in pregnant cows (related to stress in mammals). A measure was taken in each individual twice; once as a baseline measure, and once after a treatment of soothing music being played to the cows for 3 hours per day. The prediction is that the mean level of cortisol will decrease relative to baseline after experiencing the music treatment.
To carry out a t-test on paired-sample data we have to: 1) find the mean of the difference of all the pairs and 2) evaluate whether this is significantly different from zero. We already know how to do this! This is just an application of the one-sample t-test, where the expected value (i.e. the null hypothesis) is 0. The thing to realise here, is that although we started out with two sets of values, what matters is the sample of differences between pairs and the population we’re interested in a ‘population of differences.’ Thankfully, R has an in-built procedure for doing paired-sample t-tests:
Paired t-test
data: cort.t0 and cort.t1
t = -3.7324, df = 19, p-value = 0.001412
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
-0.31605728 -0.08894272
sample estimates:
mean difference
-0.2025
7 Non-parametric alternatives to t-tests
There are several non-parametric procedures (all available in R) that provide similar types of test to the t-tests that we have already seen. These are useful when the assumptions of the t-test are not met. The most common of these are the Wilcoxon signed-rank test and the Mann-Whitney U test. These tests are all based on ranks, rather than the original data, and so are not affected by non-normality. They are also more robust to outliers than the t-test. However, they are less powerful than the t-test when the assumptions of the t-test are met. This means that they are less likely to detect a real effect when one exists.
7.1 Wilcoxon signed-rank test
The most widely used non-parametric equivalent to the one-sample t-test is the Wilcoxon signed-rank test. The test can be used for any situation requiring a test to compare the median of a sample against a single value. However, it is almost always used to analyse data collected using a paired-sample design, so we’ll focus on that particular application of the test. The Wilcoxon signed-rank test makes less stringent assumptions than the t-test, but it does make some assumptions:
The variable being tested is measured on ordinal, interval, or ratio scales;
The (population) distribution of the variable is approximately symmetric.
The first assumption is simple enough—the variable can be anything but nominal. The second assumption essentially means that it doesn’t matter what form the distribution of the variable looks like as long as it is symmetric—it would not be satisfied if the distribution were strongly right- or left-skewed.
As with the t-test, when applied to paired-sample data the Wilcoxon signed-rank test starts by finding the differences between all the pairs, and then tests whether these differences are significantly different form zero. The distribution under consideration is the distribution of differences between the pairs. Remember, this distribution will often be approximately normal even when the connected samples are not themselves drawn from a normal distribution. This means that even if the samples have odd distributions, we may still find that we can use a paired-sample t-test if differences have a perfectly acceptable distribution. However, if the distribution of differences is not normal then the Wilcoxon signed-rank test provides an alternative.
Let’s consider an example where an agricultural researcher wants to compare the effectiveness of two different fertilizers – a standard fertilizer (Fertilizer A) and a new organic fertilizer (Fertilizer B) – on the yield of a particular crop. The researcher selects 20 plots of land with similar soil quality and environmental conditions. Each plot is divided into two parts. One part receives Fertilizer A and the other receives Fertilizer B. After a growing season, the yield (in kilograms) of the crop is measured from both parts of each plot. The data are shown below:
Let’s carry out a Wilcoxon signed-rank test to see if there is a significant difference in the yield of the crop between the two fertilizers. The null hypothesis is that there is no difference in yield between the two fertilizers. The alternative hypothesis is that there is a difference in yield between the two fertilizers. We can use the wilcox.test() function to carry out the test:
# Wilcoxon signed-rank testwilcox.test(yield_A, yield_B, mu =0, paired =TRUE, data = yield_data)
Wilcoxon signed rank exact test
data: yield_A and yield_B
V = 74, p-value = 0.2611
alternative hypothesis: true location shift is not equal to 0
The output of the test shows that the p-value is 0.261 This is greater than 0.05, so we can accept the null hypothesis and conclude that there is no significant difference in yield between the two fertilizers.
7.2 Mann-Whitney U test
The Mann-Whitney U-test is the non-parametric equivalent to the independent two-sample t-test. The test can be used for any situation requiring a test to compare the median of two samples. The assumptions of the Mann-Whitney U-test are:
The variable being tested is measured on ordinal, interval, or ratio scales;
The observations from both groups are independent of one another.
The first two assumptions are straightforward—data can be anything but nominal, and as with a paired-sample t-test, there must not be any dependence between the observations. Though not strictly necessary for the Mann-Whitney U-test to be valid, we usually add a third assumption:
The distribution of the variable in each group is similar (apart than the fact that they have a different central tendency)
This assumption essentially means that it doesn’t matter what the distributions of the two samples are like, but they should be at least roughly similar—it would not be satisfied if we plan to compare data from a strongly right-skewed distribution with data from a strongly left-skewed distribution. If this assumption is not satisfied the test can still be used, but a significant result is hard to interpret (so don’t bother!).
When all three of the above assumptions are satisfied the Mann-Whitney U-test is used as a way of looking for differences between the central tendency of two distributions. A two-sample t-test evaluates the statistical significance of differences between two means. The null hypothesis of the Mann-Whitney U-test (if all three of the above assumptions) is that the two distributions have the same median . A significant p value therefore indicates that the medians are likely to be different.
Let’s consider an example where an agricultural researcher is investigating the effectiveness of two different irrigation methods – Drip Irrigation (Method A) and Flood Irrigation (Method B) – on the yield of a crop. The researcher selects 40 plots of land with similar soil quality and environmental conditions. 20 plots are randomly assigned to use Drip Irrigation (Method A), and the remaining 20 are assigned Flood Irrigation (Method B). After a growing season, the yield (in kilograms) of the crop is measured from each plot. The data are shown below:
Let’s carry out a Mann-Whitney U-test to see if there is a significant difference in the yield of the crop between the two irrigation methods. The null hypothesis is that there is no difference in yield between the two irrigation methods. The alternative hypothesis is that there is a difference in yield between the two irrigation methods. We can use the wilcox.test() function to carry out the test:
# Mann-Whitney U testwilcox.test(yield ~ method, mu =0, paired =FALSE, data = yield_data_2)
Wilcoxon rank sum exact test
data: yield by method
W = 316, p-value = 0.001291
alternative hypothesis: true location shift is not equal to 0
You will note that this is the same function we used to carry out the Wilcoxon signed-rank test. The only difference is that we have specified the paired argument as FALSE (the default is TRUE for the Wilcoxon signed-rank test). The output of the test shows that the p-value is 0.001. This is less than 0.05, so we can reject the null hypothesis and conclude that there is a significant difference in yield between the two irrigation methods.
8 Activities
8.1 Paired-sample t-test
Create a visualisation for the paired-sample t-test example above and write a summary of the result.
A paired-sample t-test was used to compare the mean level of cortisol in pregnant cows before and after a treatment of soothing music. The mean level of cortisol was significantly higher after the treatment (M = 0.83) than before (M = 0.67), t(19) = 3.7, p < 0.001, d = 0.20.
8.2 Choose the correct t-test
For each of the following scenarios, choose the correct t-test to use:
A botanist wants to test the effect of a new nutrient supplement on the growth of a specific plant species. She measures the height of 30 plants before and after applying the supplement for a month. She wants to know if the supplement has significantly changed the plants’ height;
An agronomist is comparing the effectiveness of two types of fertilizers, Fertilizer X and Fertilizer Y, on the yield of corn. He applies Fertilizer X to 15 fields and Fertilizer Y to another 15 different fields. After the growing season, he records the corn yield from each field;
A medical researcher is testing the effect of a new drug on blood pressure. She selects a group of 40 patients and randomly assigns 20 to receive the drug and the other 20 to receive a placebo. After a month, she compares the average blood pressure between the two groups.
💡 Click here to view the correct answers
Paired-sample t-test as the same plants are measured before and after the treatment;
Two-sample t-test as the two groups are independent;
Two-sample t-test as the two groups are indpendent.
8.3 Practice with t-tests
Imagine an agricultural researcher is interested in the level of a specific nutrient, say nitrogen, in the soil of a particular region. The researcher has a hypothesis that the average nitrogen level in the soil is different from a standard value considered ideal for a certain crop. The standard ideal nitrogen level is, for instance, 30 units (this could be parts per million, ppm). The researcher collects soil samples from various locations within the region and measures the nitrogen level in each sample.
Identify which t-test is appropriate for the data;
Carry out the t-test;
Create a visualisation of the data;
Write a summary of the results.
💡 Click here to view a solution
# Define the sample_id and nitrogen_level vectorssample_id <-1:40nitrogen_level <-c(29.19762, 30.84911, 39.79354, 32.35254, 32.64644, 40.57532, 34.30458, 25.67469, 28.56574, 29.77169,38.12041, 33.79907, 34.00386, 32.55341, 29.22079,40.93457, 34.48925, 22.16691, 35.50678, 29.63604,26.66088, 30.91013, 26.86998, 28.35554, 28.87480,23.56653, 36.18894, 32.76687, 26.30932, 38.26907,34.13232, 30.52464, 36.47563, 36.39067, 36.10791,35.44320, 34.76959, 31.69044, 30.47019, 30.09764)# Combine them into a data framesoil_data <-data.frame(sample_id, nitrogen_level)# Carry out a one-sample t-testt.test(soil_data$nitrogen_level, mu =30)# Create a boxplot with expected nitrogen level as a red lineggplot(soil_data, aes(x ='', y = nitrogen_level)) +geom_boxplot() +geom_hline(yintercept =30, col ='red', lwd =2) +theme_grey(base_size =22) +xlab("") +ylab("Nitrogen level (ppm)")# Calulate mean and standard deviationmean(soil_data$nitrogen_level)sd(soil_data$nitrogen_level)
When reporting the results of a one-sample t-test, it’s important to include key information such as the test statistic (t-value), degrees of freedom (df), p-value, confidence interval for the mean, and the sample estimate of the mean. Here’s how you can report these results:
A one-sample t-test was conducted to compare the mean nitrogen level in soil samples to the standard ideal level of 30 ppm. The analysis revealed that the average nitrogen level in the soil samples (M = 32.23 ppm, SD = 4.49 ppm) was significantly different from the standard level, t(39) = 3.14, p = 0.00325. The 95% confidence interval for the mean nitrogen level ranged from 30.79 to 33.66 ppm.
These results suggest that the nitrogen level in the soil is significantly higher than the standard ideal level of 30 ppm.
Footnotes
The term ‘independent’ typically refers to a scenario where two events or variables are not influenced by each other. This means the occurrence of one event or the value of one variable does not affect the occurrence of the other event or the value of the other variable.↩︎