Create a good header section and table of contents
Save the script file with an informative name
set your working directory
Aim to make the script a future reference for doing things in R!
3 Generalised Linear Models
In this lab we will fit general linear models to data, implemented in the R command glm(). A generalized linear model is useful when the response variable has a distribution other than the Gaussian distribution and when a transformation of the data is undesirable or impossible. Example situations include binary response data (1 or 0, dead or alive) or data that are counts (number of offspring, leaves, etc.). The approach is also useful in the analysis of contingency tables. We will go through a couple of examples together and then you will work on a problem.
4 Binomial GLM
The song sparrow population on the island of Mandarte has been studied for many years by Jamie Smith, Peter Arcese, and collaborators. The birds were measured and banded and their fates on the island have recorded over many years. Here we will look for evidence of natural selection using the relationship between phenotypes and survival.
The data file songsparrow.csv gives survival of young-of-the-year females over their first winter (1=survived, 0=died). The file includes measurements of beak and body dimensions: body mass (g), wing length, tarsus length, beak length, beak depth, beak width (all in mm), year of birth, and survival.
4.1 Read and examine data
Let’s start by reading the data from the file and inspecting the first few lines to make sure it was read correctly:
# Read the datax <-read.csv("data/songsparrow.csv", stringsAsFactors =FALSE)# Inspect the first few lineshead(x)
mass wing tarsus blength bdepth bwidth year sex survival
1 23.7 67.0 17.7 9.1 5.9 6.8 1978 f 1
2 23.1 65.0 19.5 9.5 5.9 7.0 1978 f 0
3 21.8 65.2 19.6 8.7 6.0 6.7 1978 f 0
4 21.7 66.0 18.2 8.4 6.2 6.8 1978 f 1
5 22.5 64.3 19.5 8.5 5.8 6.6 1978 f 1
6 22.9 65.8 19.6 8.9 5.8 6.6 1978 f 1
We’ll be comparing survival probabilities among different years. To this end, let’s make sure that year is a categorical variable in the data frame as it is currently a character variable:
# Year as categorical variablex$year <-as.character(x$year)
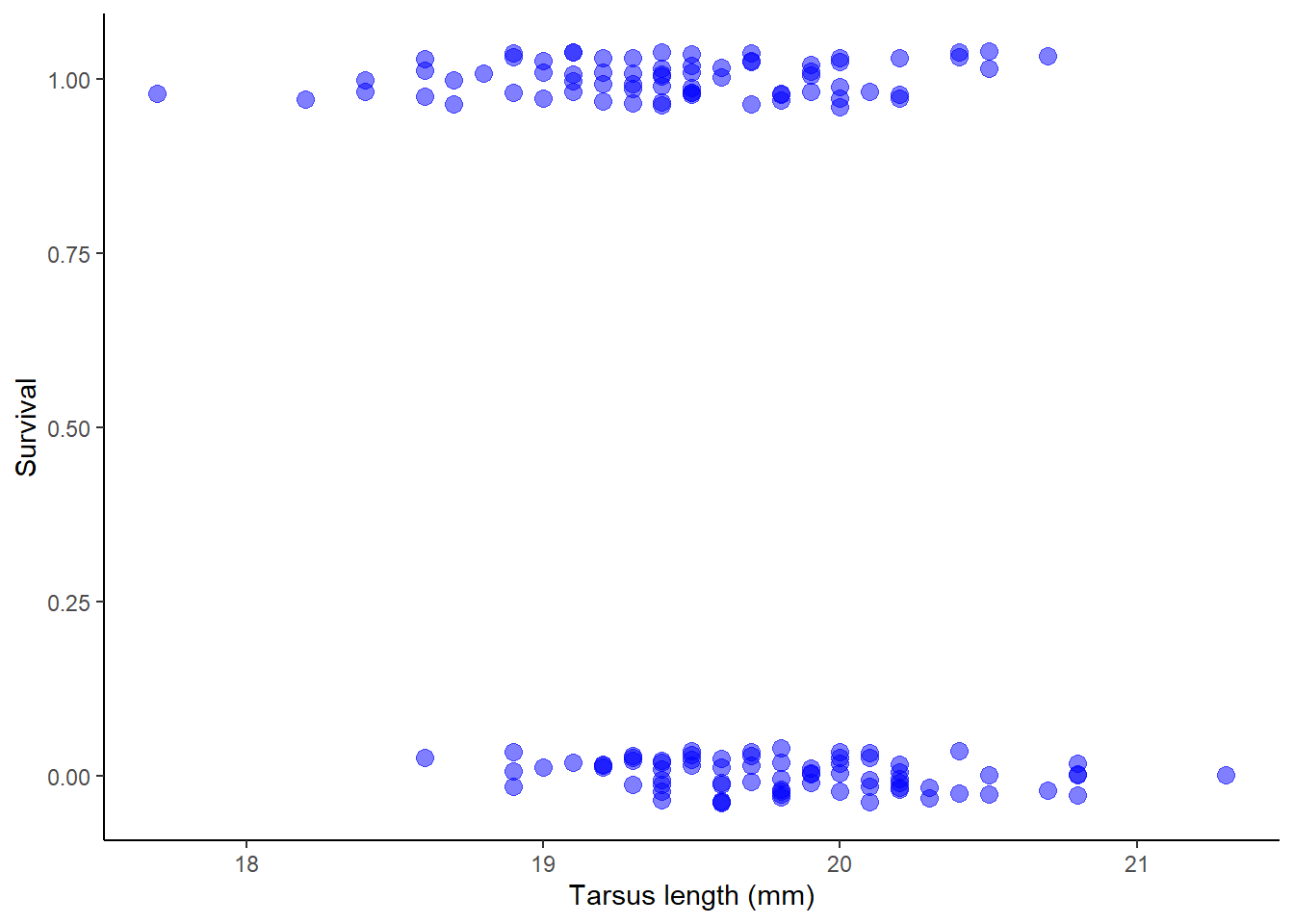
Next, let’s plot survival against tarsus length of female sparrows using a method to reduce the overlap of points (the response variable is 0 or 1) to see the patterns more clearly. We will use the ggplot2 package for plotting:
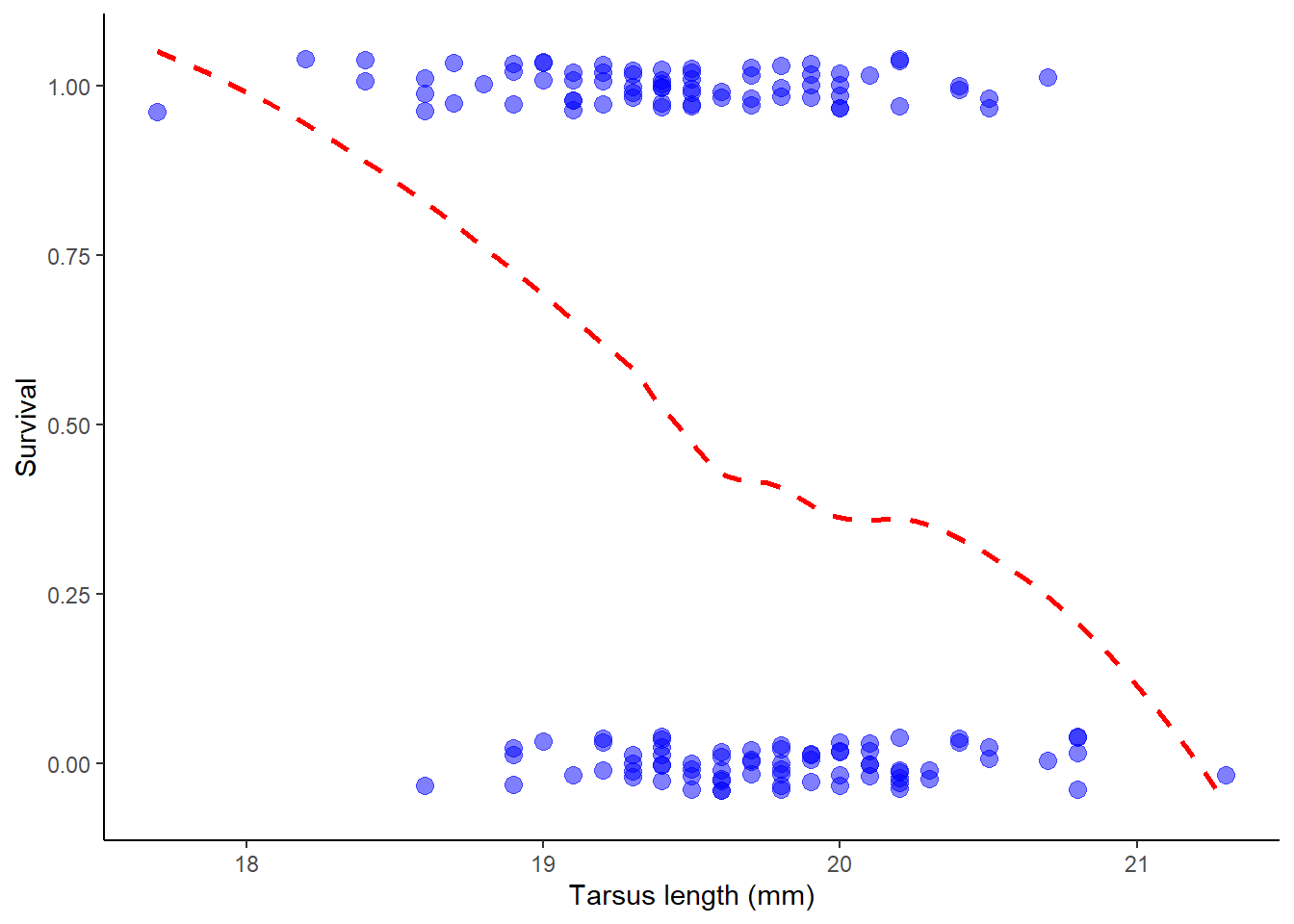
Upon examining the plot can you visualise a trend? Let’s use a smoothing method to see if any trend is present (most methods won’t constrain the curve to lie between 0 and 1, but at least we’ll get an idea):
# Plot survival against tarsus lengthggplot(x, aes(tarsus, survival)) +geom_jitter(color ="blue", size =3, height =0.04, width =0, alpha =0.5) +geom_smooth(method ="loess", se =FALSE, color ="red", size =1,lty =2) +labs(x ="Tarsus length (mm)", y ="Survival") +theme_classic()
It looks like there might be a negative trend between the two variables. Let’s see if we can quantify this relationship.
4.2 Fit a generalised linear model
We will ignore the fact that the data are from multiple years. We will have the option later to add year to the model to see if it makes a difference!
As the response variable is binary. What probability distribution is appropriate to describe the error distribution around a model fit and what is an appropriate link function?
💡 Click here to view a solution
The response variable is binary, so the error distribution is binomial. The link function is the logit function.
Okay, let’s fit a generalised linear model to the data on survival and tarsus length. We will use the glm() function in R:
# Fit a generalised linear modelz <-glm(survival ~ tarsus, # Model formuladata = x, # Data framefamily =binomial(link ="logit")) # Error distribution
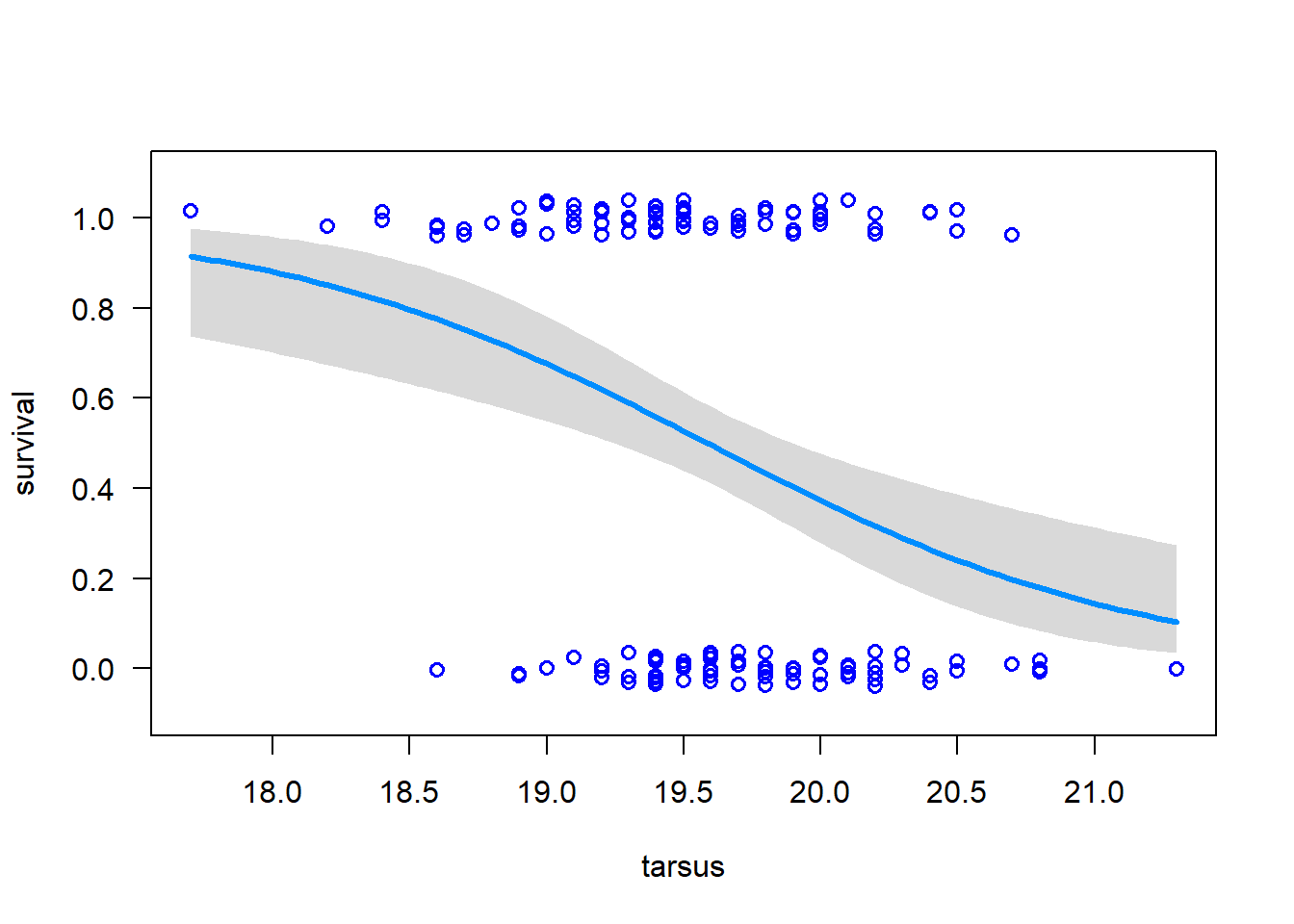
This hasn’t given us any output, but we don’t need to worry about that now. Let’s use visreg() to visualise the model fit:
# Load visreglibrary(visreg)# Visualise the model fitvisreg(z, xvar ="tarsus", scale ='response',rug =FALSE, ylim =c(-.1, 1.1))points(jitter(survival, 0.2) ~ tarsus, data = x, pch =1, col ="blue", cex =1, lwd =1.5)
The solid line is the fitted regression curve. The dashed lines are the 95% confidence intervals for the fitted curve. The points are the data. The scale = 'response' argument tells visreg() to plot the response variable on the y-axis. The rug = FALSE argument tells visreg() not to plot the rug plot. The ylim = c(-.1, 1.1) argument tells visreg() to set the y-axis limits to -0.1 and 1.1. The points() function adds the data points to the plot. Now let’s obtain the estimated regression coefficients for the fitted model.
The estimated regression coefficients are:
# Estimated regression coefficientssummary(z)
Call:
glm(formula = survival ~ tarsus, family = binomial(link = "logit"),
data = x)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 24.6361 6.7455 3.652 0.000260 ***
tarsus -1.2578 0.3437 -3.659 0.000253 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 200.95 on 144 degrees of freedom
Residual deviance: 185.04 on 143 degrees of freedom
AIC: 189.04
Number of Fisher Scoring iterations: 4
What is the interpretation of these coefficients? On a piece of paper, write down the complete formula for the model shown in the visreg plot.
💡 Click here to view a solution
With an intercept of 24.6 and tarsus length coefficient of -1.26, the complete formula for the model shown in the visreg plot is:
logit(p) = 24.6 - 1.26 * x
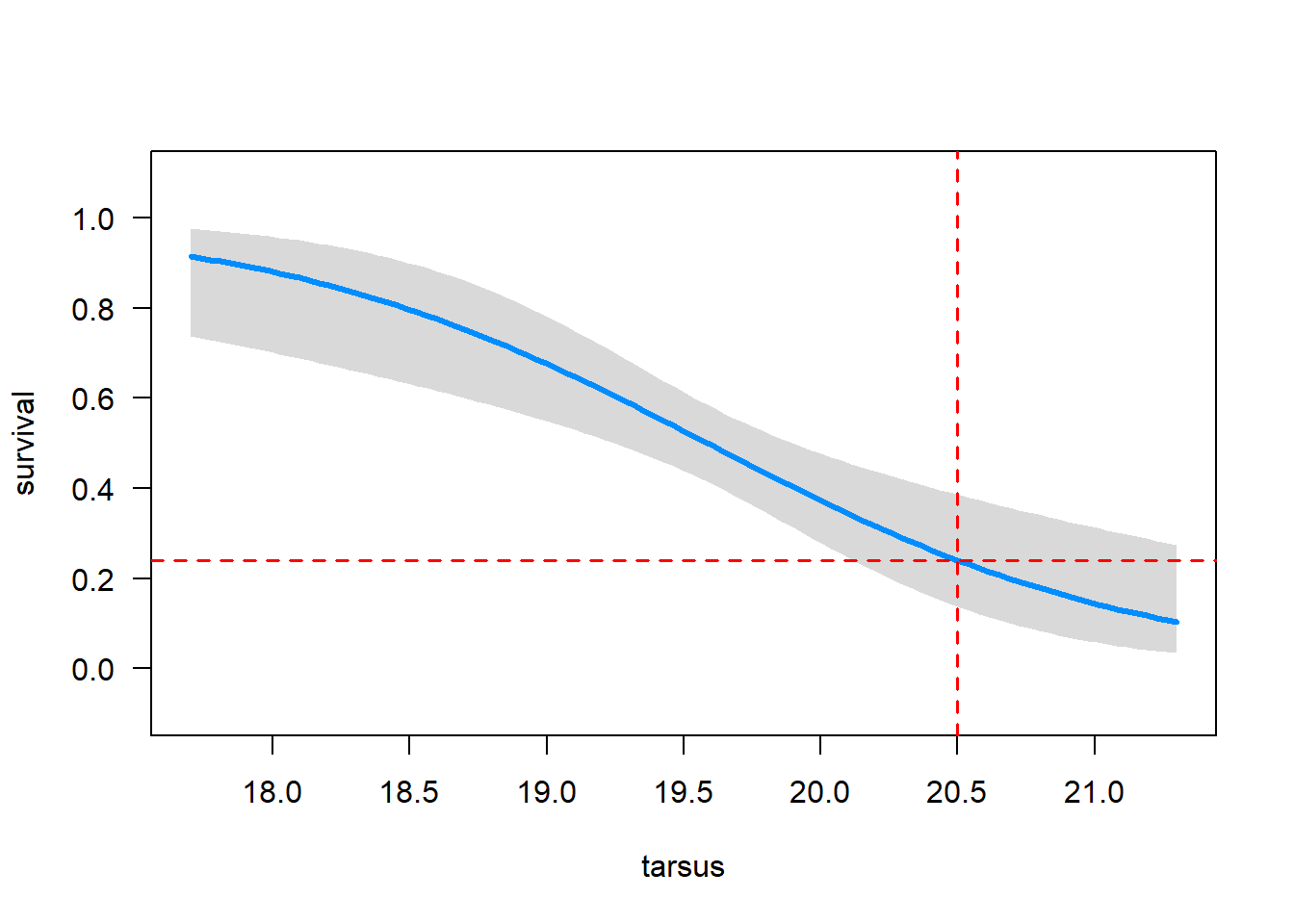
We can use the coefficients to calculate the predicted survival probability of a song sparrow having tarsus length 20.5 mm*:
# Predicted survival probabilitypredict(z, # Model objectnewdata =data.frame(tarsus =20.5), # New datatype ="response") # Response
1
0.2407491
Does the result agree with your plot of the fitted regression curve?
💡 Click here to view a solution
# Visualise the model fitvisreg(z, xvar ="tarsus", scale ='response',rug =FALSE, ylim =c(-.1, 1.1))# Add line at tarsus length 20.5 mmabline(v =20.5, lty =2, col ="red", lwd =1.5)# Corresponding horizontal line that meets the vertical line abline(h =0.24, lty =2, col ="red", lwd =1.5)
Yes!
We can also calculate the likelihood-based 95% confidence interval for the logistic regression coefficients. Confidence intervals provides a deeper insight into the reliability and significance of the model’s predictors:
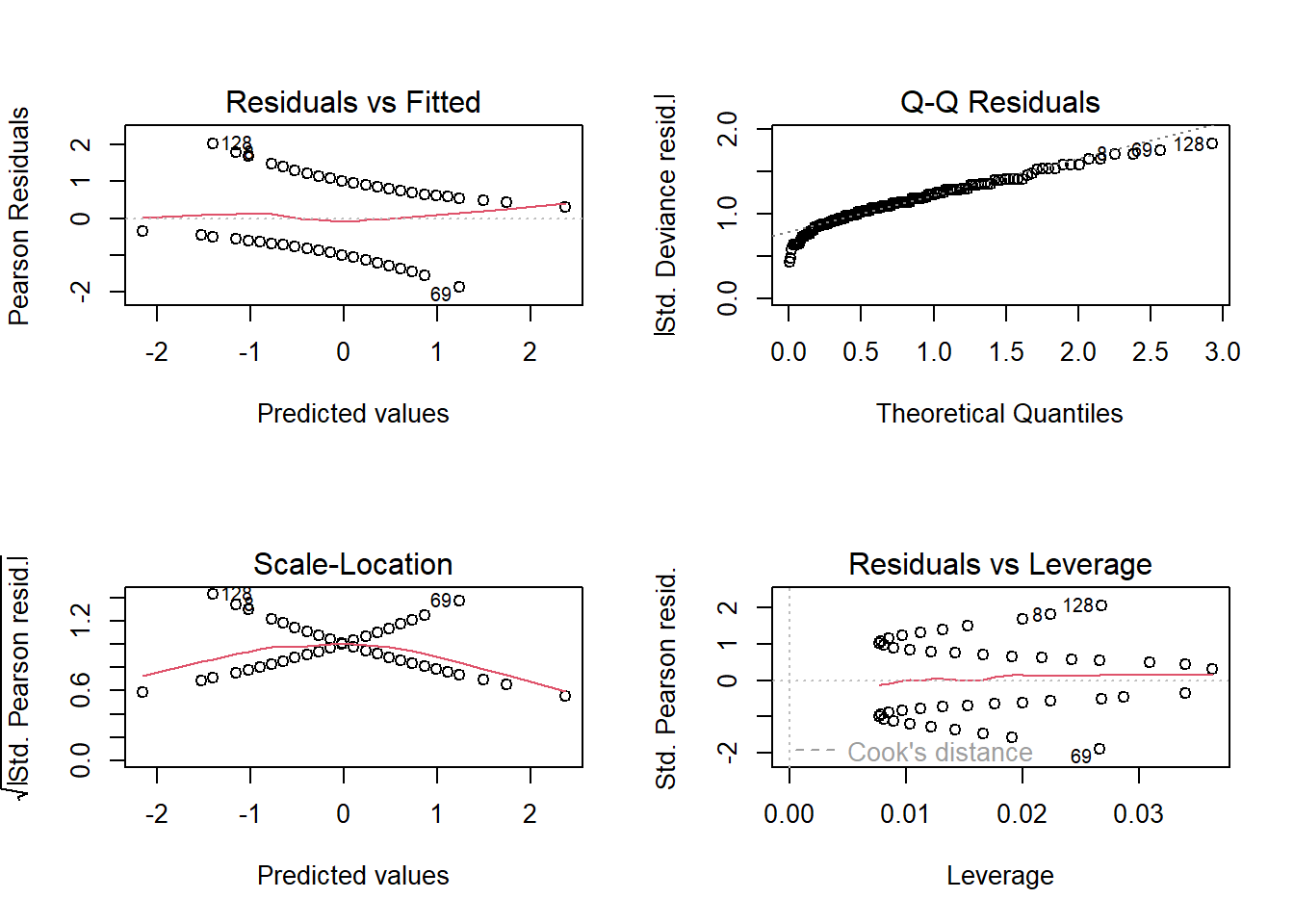
We can use the plot() function to produce a series of diagnostic plots for the fitted model:
# Set up the plot areapar(mfrow =c(2, 2))# Plot the model diagnosticsplot(z)
What can you determine from these plots - are there any problems with the model fit?
💡 Click here to view a solution
The model seems to be reasonably well-fitted to the data, with residuals showing no obvious patterns of misspecification and most residuals falling around the zero line. The residuals appear mostly homoscedastic, although there may be some slight concerns about heteroscedasticity as suggested by the Scale-Location plot. The Normal Q-Q plot indicates that residuals are not perfectly normally distributed, with some deviation at the upper end.
The key assumptions specific to a binomial GLM include:
The response variable is binary (e.g., success/failure, yes/no, 1/0). In some cases, it can also be a proportion, representing the number of successes out of a number of trials;
Each observation should be independent of the others. This is a crucial assumption in binomial GLM and refers to the idea that the outcome of one trial does not influence the outcome of another;
There should be a linear relationship between the logit of the expected value (the log-odds) and the explanatory variables. The logit function is the most common link function used in binomial GLMs and it is defined as the log of the odds of the probability of success;
The explanatory variables should not be perfectly collinear. This means that no explanatory variable is a perfect linear combination of others;
The binomial distribution assumes that the mean and variance are linked (the variance is a function of the mean). Overdispersion occurs when the variance is greater than the mean. This can be checked by comparing the residual deviance to the residual degrees of freedom. If the residual deviance is greater than the residual degrees of freedom, then there is overdispersion.
4.4 Reporting the results
In a binomial GLM assessing the impact of tarsus length on song sparrow survival, the coefficient for tarsus length was significantly negative (-1.2578, SE = 0.3437, z = -3.659, p < 0.001), indicating a decrease in survival probability with increasing tarsus length. The model, with an intercept of 24.6361 (SE = 6.7455, z = 3.652, p < 0.001), achieved a good fit, evident from a null deviance of 200.95 on 144 degrees of freedom and a residual deviance of 185.04 on 143 degrees of freedom, with an AIC of 189.04.
5 Poisson GLM
The horseshoe crab, Limulus polyphemus, has two alternative male reproductive morphs. Some males attach to females with a special appendage. The females bring these males with them when they crawl onto beaches to dig a nest and lay eggs, which the male then fertilizes. Other males are satellites, which are unattached to females but crowd around nesting pairs and obtain fertilizations. What attributes of a female horseshoe crab determine the number of satellite males she attracts on the beaches?
The data file satellites.csv provides measurements of 173 female horseshoe crabs and records the number of satellites they attracted. The data were gathered by Brockman (1996. Satellite male groups in horseshoe crabs, Limulus polyphemus. Ethology 102:1-21) and were published by Agresti (2002, Categorical data analysis, 2nd ed. Wiley). The variables are female color, spine condition, carapace width (cm), mass (kg), and number of satellite males.
5.1 Read and examine data
Let’s start by reading the data from the file and inspecting the first few lines to make sure it was read correctly:
# Read the data from the filesatellites <-read.csv("data/satellites.csv")# View the first few lines of datahead(satellites)
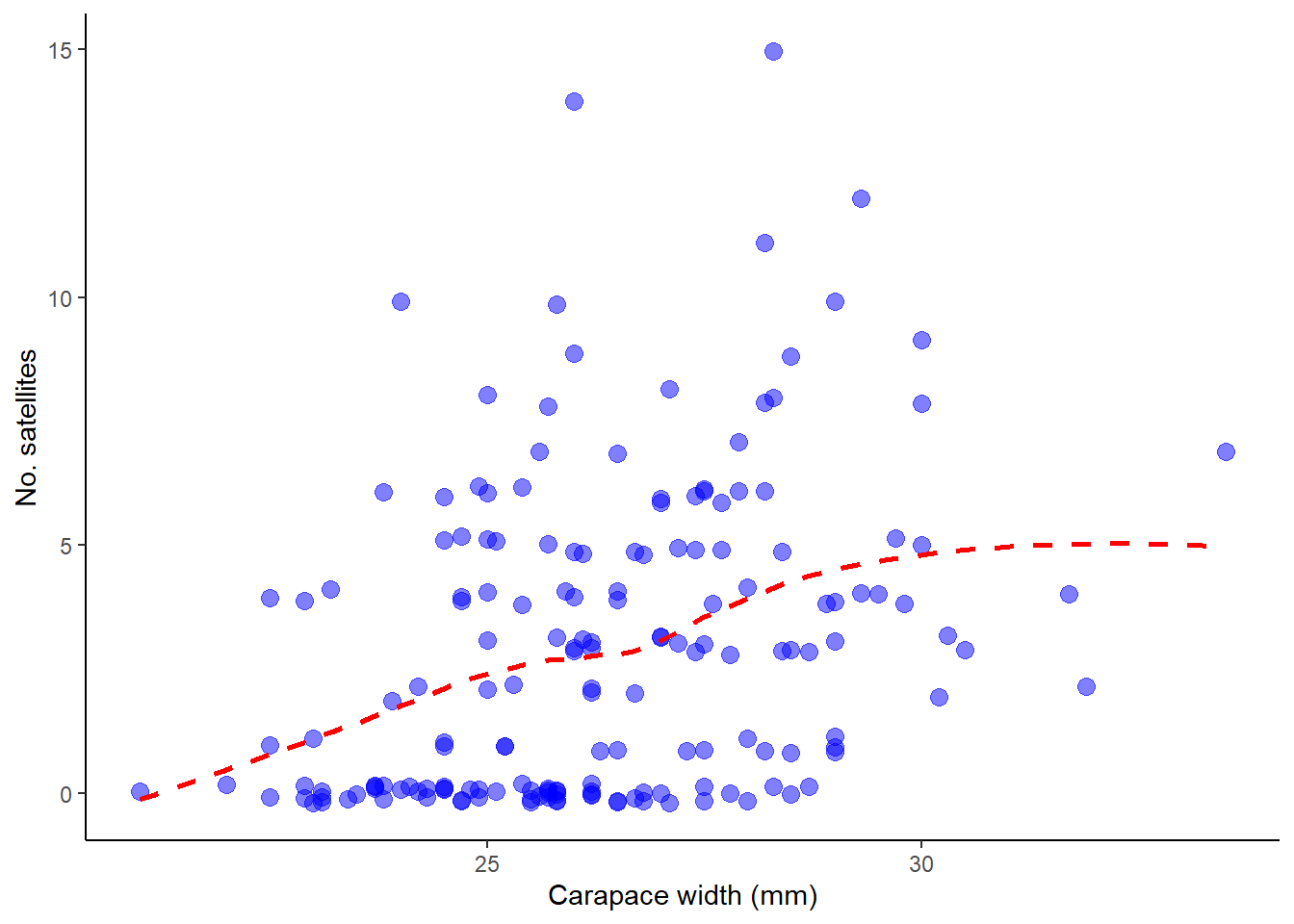
Looks good! Now let’s plot the number of satellites against the width of the carapace using ggplot2, a measure of female body size and fit a smooth curve to examine the trend:
# Plot the number of satellites against the width of the carapaceggplot(satellites, aes(width.cm, nsatellites)) +geom_jitter(color ="blue", size =3, height =0.2, width =0, alpha =0.5) +geom_smooth(method ="loess", size =1,col ="red", lty =2, se =FALSE) +labs(x ="Carapace width (mm)", y ="No. satellites") +theme_classic()
5.2 Fit a generalised linear model
Let’s fit a generalised linear model to the relationship between number of satellite males and female carapace width. First, consider the following:
What type of variable is the number of satellites?
What probability distribution might be appropriate to describe the error distribution around a model fit?
What is the appropriate link function?
💡 Click here to view a solution
The number of satellites is a count variable, and so a Poisson distribution is appropriate. The link function is log.
Now let’s fit the model:
# Fit a Poisson GLM to the dataz <-glm(nsatellites ~ width.cm, data = satellites, family =poisson(link ="log"))
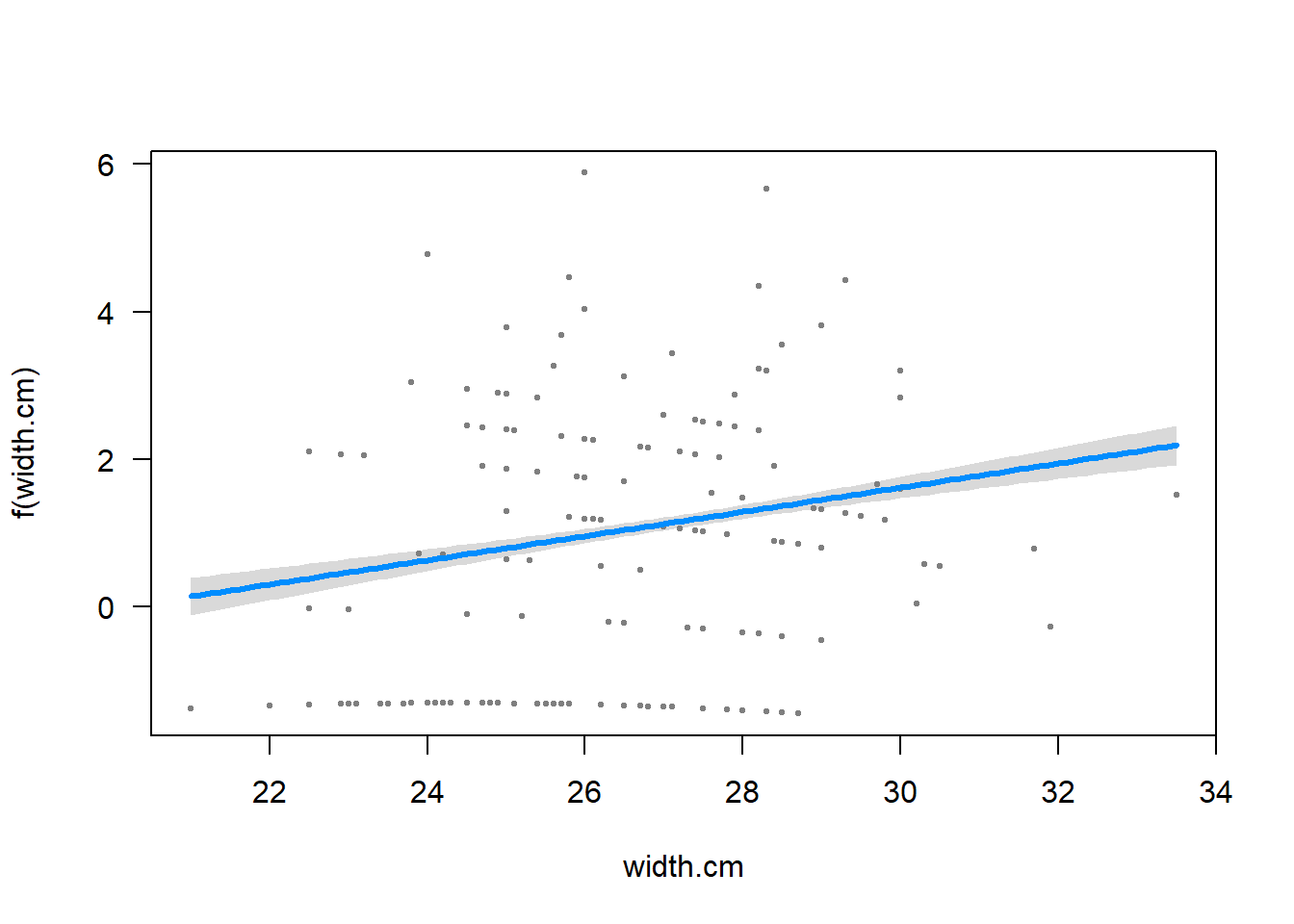
Let’s use visreg() to visualise the model fit:
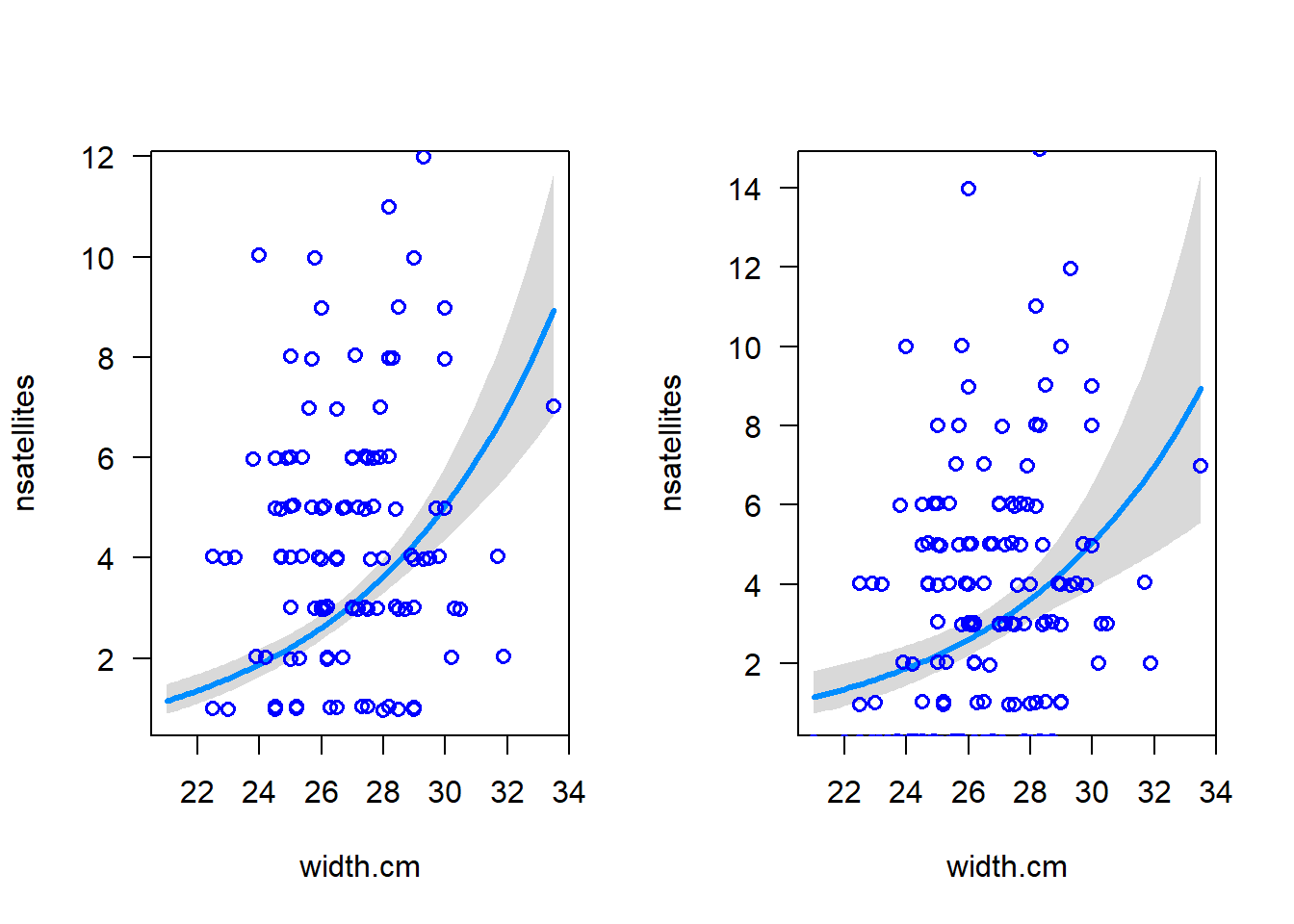
# Visualise model fit (transformed scale)visreg(z, xvar ="width.cm")
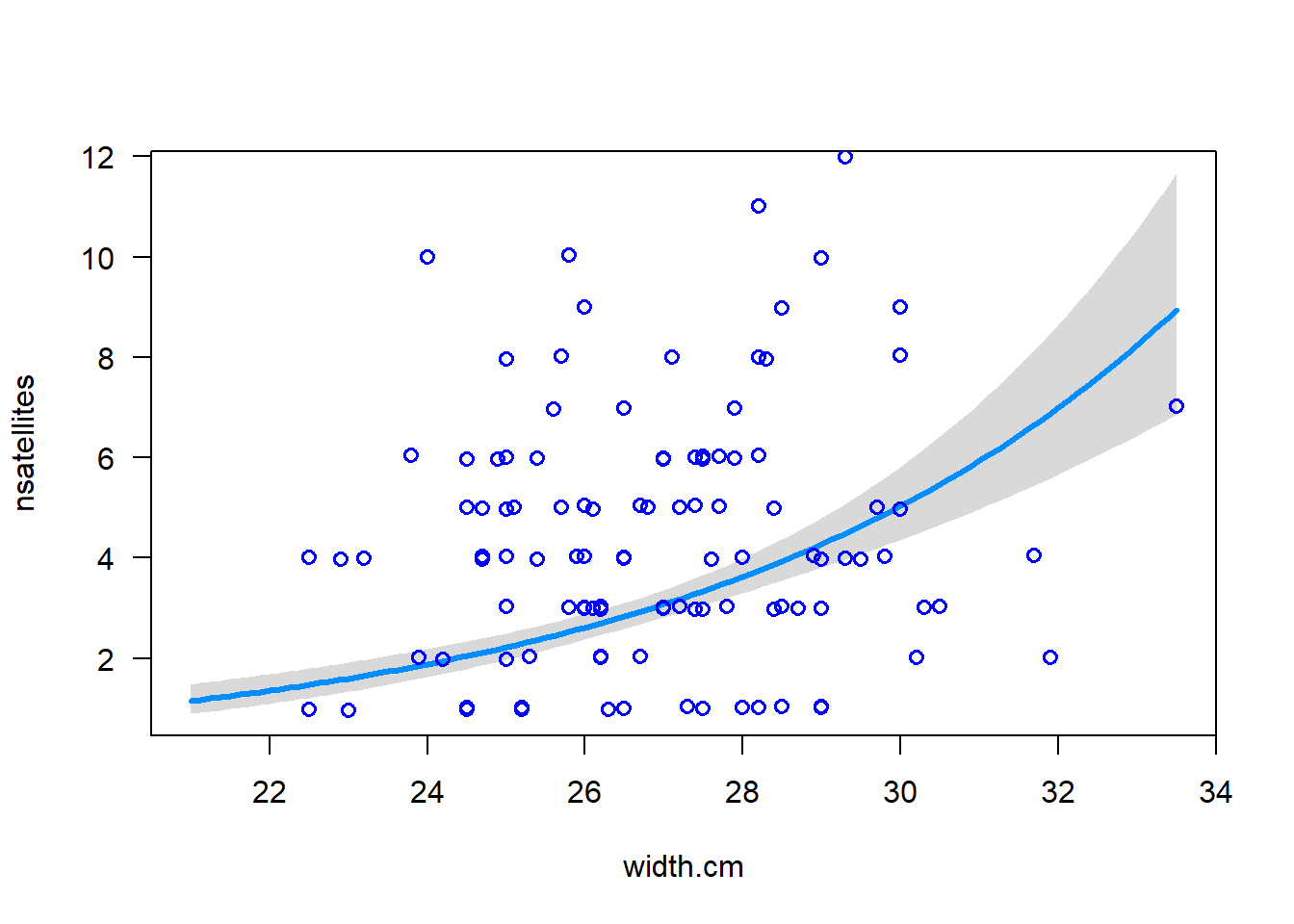
This plot reminds us that on the transformed scale, glm() is fitting a straight line relationship. (Don’t worry about the points – they aren’t the transformed data, but rather are “working values” for the response variable from the last iteration of model fitting, which glm() uses behind the scenes to fit the model on the transformed scale). Now let’s visualise the model fit on the original data scale - note that it is curvilinear:
# Visualise the model fitvisreg(z, xvar ="width.cm", scale ="response", rug =FALSE)points(jitter(nsatellites, 0.2) ~ width.cm, data = satellites, pch =1, col ="blue", lwd =1.5)
Now let’s extract the estimated regression coefficients from the model object:
# Extract the regression coefficientssummary(z)
Call:
glm(formula = nsatellites ~ width.cm, family = poisson(link = "log"),
data = satellites)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.30476 0.54224 -6.095 1.1e-09 ***
width.cm 0.16405 0.01997 8.216 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 632.79 on 172 degrees of freedom
Residual deviance: 567.88 on 171 degrees of freedom
AIC: 927.18
Number of Fisher Scoring iterations: 6
What is the interpretation of these coefficients? On a piece of paper, write down the complete formula for your fitted model.
💡 Click here to view a solution
With an intercept of -3.305 and width coefficient of 0.164, the complete formula for the model shown in the visreg plot is:
\[\log(\text{number of satellites}) = -3.365 + 0.164 \times \text{carapace width}\]
The most useful estimate is that for the slope: exp(slope) represents the multiple to the response variable accompanying a 1-unit change in the explanatory variable. In other words, if the slope were found to be 1.2, this would indicate that a 1 cm increase in carapace width of a female is accompanied by a 1.2-fold increase in the number of male satellites. You can view this by running:
# Exponentiate the slope coefficientexp(0.164)
[1] 1.178214
# Exponentiate the slope coefficient using the coef() functionexp(coef(z))
(Intercept) width.cm
0.03670812 1.17826744
Now let’s test the null hypothesis of no relationship between number of satellite males and female carapace width:
Notice how small the P-value is for the null hypothesis test for the slope. I’m afraid that this is a little optimistic. When we extracted the regression coefficients from the model object, we saw the following line of output: “(Dispersion parameter for poisson family taken to be 1)”. What are we really assuming* here?
💡 Click here to view a solution
We are assuming that the mean-variance relationship is linear, i.e. that the variance of the response variable is equal to the mean. This is a common assumption for Poisson regression models.
If we do not want to rely on this assumption (or you wanted to estimate the dispersion parameter), what option is available to you? Refit a generalized linear model without making the assumption that the dispersion parameter is 1.
So what should we use? To find out we can extract and examine the coefficients of a new glm model object:
# Extract the coefficients of a new modelz2 <-glm(nsatellites ~ width.cm, family =quasipoisson(link ="log"), data = satellites)# Extract the coefficientssummary(z2)
Call:
glm(formula = nsatellites ~ width.cm, family = quasipoisson(link = "log"),
data = satellites)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.30476 0.96729 -3.417 0.000793 ***
width.cm 0.16405 0.03562 4.606 7.99e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for quasipoisson family taken to be 3.182205)
Null deviance: 632.79 on 172 degrees of freedom
Residual deviance: 567.88 on 171 degrees of freedom
AIC: NA
Number of Fisher Scoring iterations: 6
Examine the estimated dispersion parameter. Is it close to 1? On this basis, which of the two glm fits to the same data would you regard as the more reliable?
💡 Click here to view a solution
The estimated dispersion parameter is 3.1, which is not close to 1. This suggests that the quasipoisson model is more reliable.
How do the regression coefficients of this new fit compare with the estimates from the earlier model fit:
# Extract the coefficientssummary(z2)
Call:
glm(formula = nsatellites ~ width.cm, family = quasipoisson(link = "log"),
data = satellites)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -3.30476 0.96729 -3.417 0.000793 ***
width.cm 0.16405 0.03562 4.606 7.99e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for quasipoisson family taken to be 3.182205)
Null deviance: 632.79 on 172 degrees of freedom
Residual deviance: 567.88 on 171 degrees of freedom
AIC: NA
Number of Fisher Scoring iterations: 6
How do the standard errors compare? Why are they larger** this time?
💡 Click here to view a solution
The standard errors are larger because the dispersion parameter is greater than 1. This means that the variance of the response variable is greater than the mean, and so the standard errors are larger.
Now let’s Visualise the new model fit and compare with the plot of the earlier fit:
# Sey up the graph panelpar(mfrow =c(1, 2))# Visualise the model fitvisreg(z, xvar ="width.cm", scale ="response", rug =FALSE)points(jitter(nsatellites, 0.2) ~ width.cm, data = satellites, pch =1, col ="blue", lwd =1.5)# Visualise the model fitvisreg(z2, xvar ="width.cm", scale ="response", rug =FALSE)points(jitter(nsatellites, 0.2) ~ width.cm, data = satellites, pch =1, col ="blue", lwd =1.5)
What difference do you notice?
💡 Click here to view a solution
The new model fit is flatter than the earlier fit. This is because the estimated dispersion parameter is greater than 1, which means that the variance of the response variable is greater than the mean.
Now let’s re-do the test of significance for the slope of the relationship between number of satellite mates and female carapace width. We have to remember to use the F test rather than the likelihood ratio test in the anova() command:
How do the results compare with those from the previous fit?
💡 Click here to view a solution
The model is now taking account of the actual amount of variance in y for each x, which is larger than that assumed by the first model we fitted.
5.3 Model Diagnostics
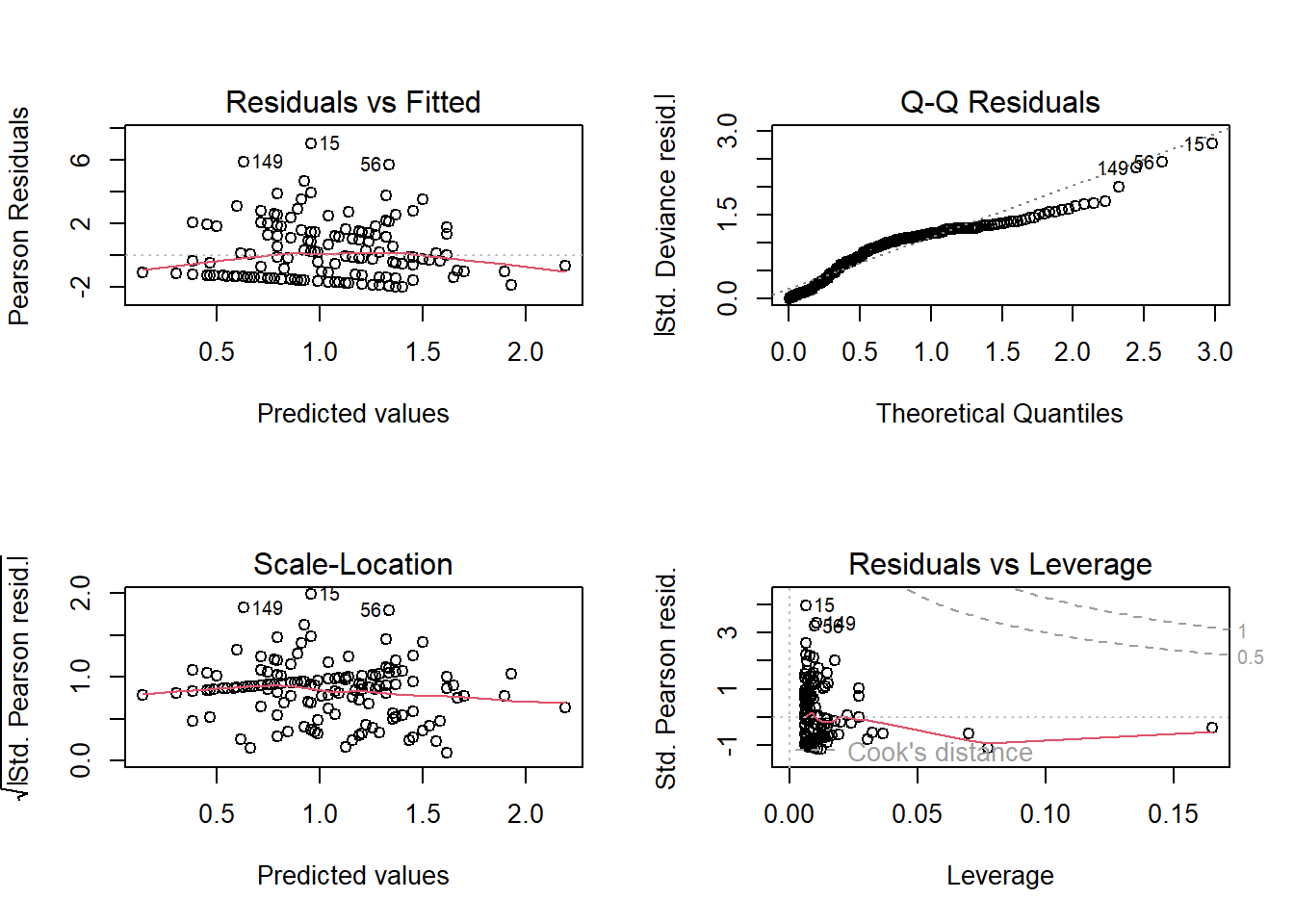
We can use the plot() function to produce a series of diagnostic plots for the fitted model:
# Set up the plot areapar(mfrow =c(2, 2))# Plot the model diagnosticsplot(z2)
What can you determine from these plots - are there any problems with the model fit?
💡 Click here to view a solution
The model appears to be a reasonable fit for the majority of the data, with no clear patterns of non-linearity or unequal variances, although potential issues with normality and a few outliers/influential points are evident. Observations 149, 15, 560, and 165 should be investigated further to determine if they are influential due to data entry errors, measurement errors, or if they are true extreme values. These points have the potential to influence the regression model disproportionately and could be a reason for concern. If these points are not errors, it may be necessary to consider robust regression techniques or transformation of the data to mitigate their influence. The potential heteroscedasticity might also need to be addressed, possibly by transforming the dependent variable or using heteroscedasticity-consistent standard errors.
The key assumptions specific to a Poisson GLM include:
The response variable is a count variable;
The response variable follows a Poisson distribution;
The mean-variance relationship is linear;
The response variable is independent of the explanatory variables.
5.4 Reporting the results
In a Quasi-Poisson regression model examining the effect of width (in cm) on the number of satellites, the coefficient for width.cm was significantly positive (estimate = 0.16405, SE = 0.03562, t = 4.606, p < 0.00001), indicating an increase in the number of satellites with increasing width. The model, with an intercept of -3.30476 (SE = 0.96729, t = -3.417, p = 0.000793), showed a dispersion parameter of 3.182205, a null deviance of 632.79 on 172 degrees of freedom, and a residual deviance of 567.88 on 171 degrees of freedom.
6 Multi-Variable GLMs
This last example is to demonstrate the use of glm() to model frequencies of different combinations of two (or more) variables in a contingency table. The presence of an interaction between the variables indicates that the relative frequencies of different categories for one variable differ between categories of the other variable. In other words, the two variables are then not independent.
Kuru is a prion disease (similar to Creutzfeldt–Jakob Disease) of the Fore people of highland New Guinea. It was once transmitted by the consumption of deceased relatives at mortuary feasts, a ritual that was ended by about 1960. Using archived tissue samples, Mead et al. (2009, New England Journal of Medicine 361: 2056-2065) investigated genetic variants that might confer resistance to kuru. The data are genotypes at codon 129 of the prion protein gene of young and elderly individuals all having the disease. Since the elderly individuals have survived long exposure to kuru, unusually common genotypes in this group might indicate resistant genotypes. The data are in the file kurudata.csv.
This example will be slightly different as you will be doing the coding!
6.1 Read and examine the data
Read the data from the file. View the first few lines of data to make sure it was read correctly.
💡 Click here to view a solution
# Read the datakuru <-read.csv("data/kurudata.csv")# View the first few lines of datahead(kuru)
Genotype Cohort
1 MM old
2 MM old
3 MM old
4 MM old
5 MM old
6 MM old
# View the structure of the datastr(kuru)
'data.frame': 152 obs. of 2 variables:
$ Genotype: chr "MM" "MM" "MM" "MM" ...
$ Cohort : chr "old" "old" "old" "old" ...
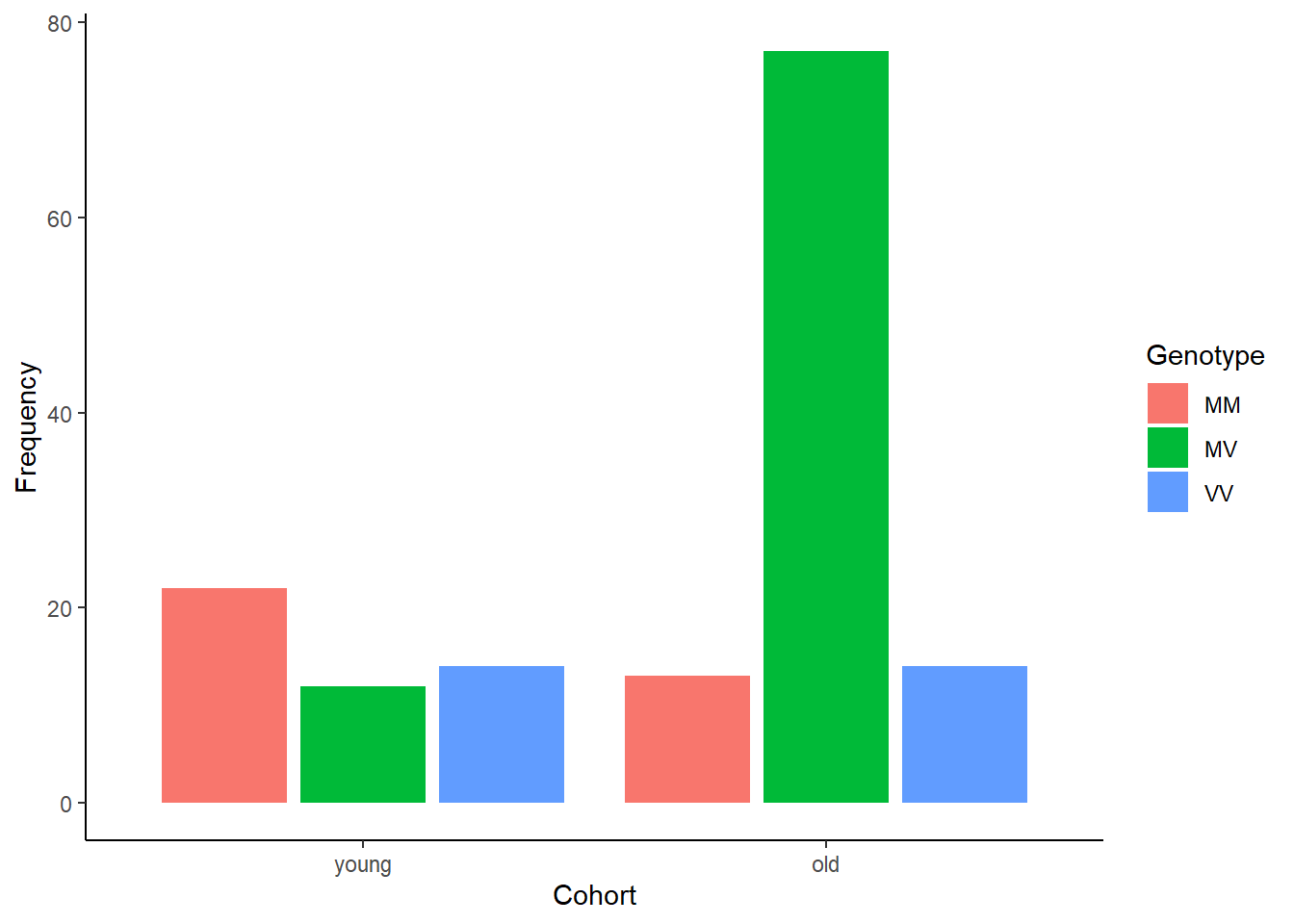
Create a contingency table comparing the frequency of the three genotypes at codon 129 of the prion protein gene of young and elderly individuals (all having the disease). Notice any pattern? By comparing the frequencies between young people and older people, which genotype is likely to be more resistant to the disease?
💡 Click here to view a solution
# Datakuru$Cohort <-factor(kuru$Cohort, levels =c("young","old")) # Create a contingency tablekurutable <-table(kuru)# View the contingency tablekurutable
Cohort
Genotype young old
MM 22 13
MV 12 77
VV 14 14
Create a grouped bar graph illustrating the relative frequencies of the three genotypes between afflicted individuals in the two age categories.
💡 Click here to view a solution
# Create a grouped bar graphggplot(kuru, aes(x = Cohort, fill = Genotype)) +geom_bar(stat ="count", position =position_dodge2(preserve="single")) +labs(x ="Cohort", y ="Frequency") +theme_classic()
6.2 Fit a generalised linear model
To model the frequencies you will first need to convert the contingency table to a “flat” frequency table using data.frame().
💡 Click here to view a solution
# Convert the contingency table to a "flat" frequency tablekuru2 <-data.frame(kurutable)
Fit a generalised linear model to the frequency table. To begin, fit the additive model, i.e., use a model formula without an interaction between the two variables genotype and age.
💡 Click here to view a solution
# Fit a generalised linear model to the frequency tablez <-glm(Freq ~ Genotype + Cohort, data = kuru2, family =poisson(link ="log"))
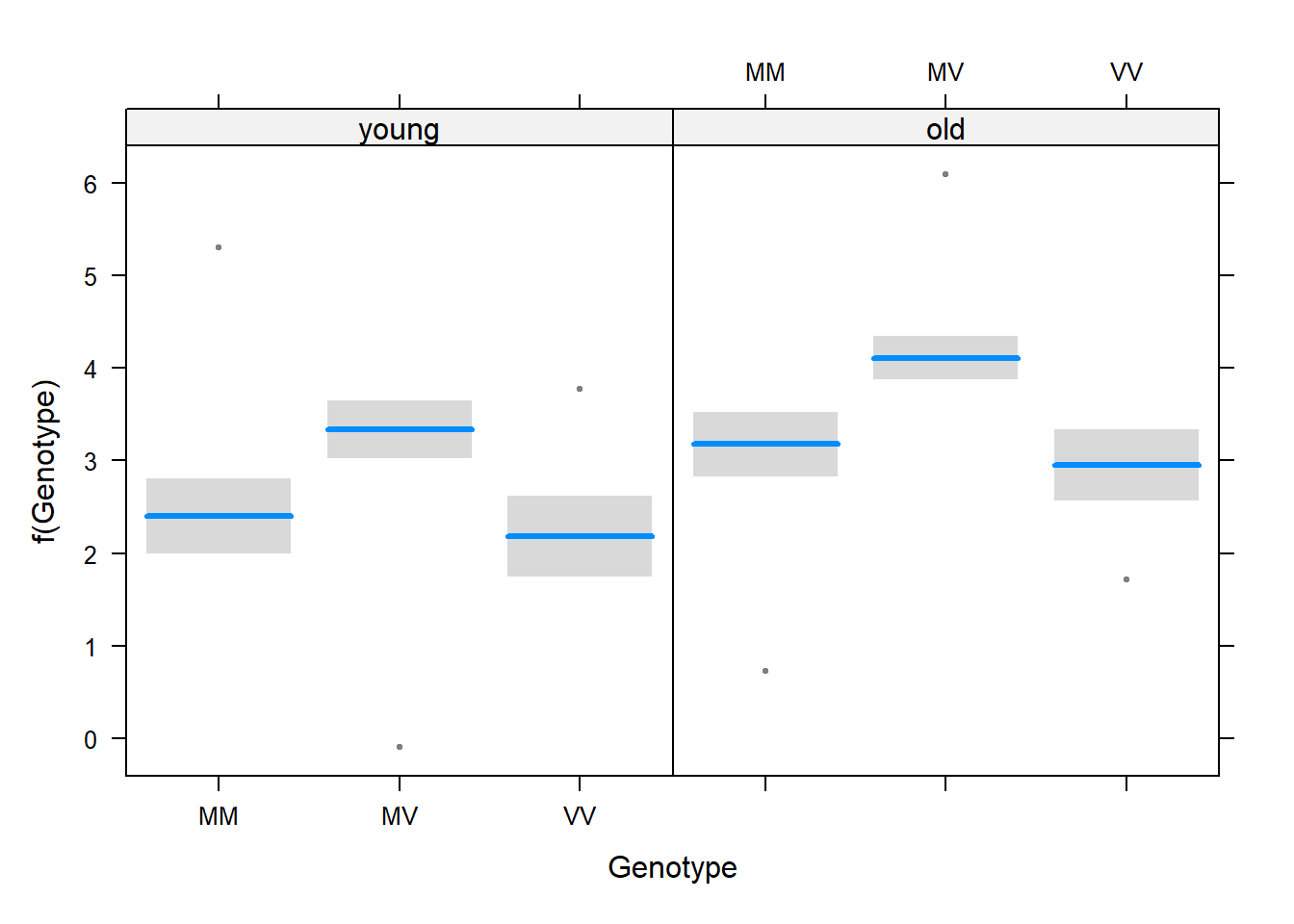
Visualize the fit of the additive model to the frequency data. Notice how the additive model is constrained from fitting the exact frequencies in each category.
💡 Click here to view a solution
# Visualize the fit of the additive model to the frequency datavisreg(z, xvar ="Genotype", by ="Cohort")
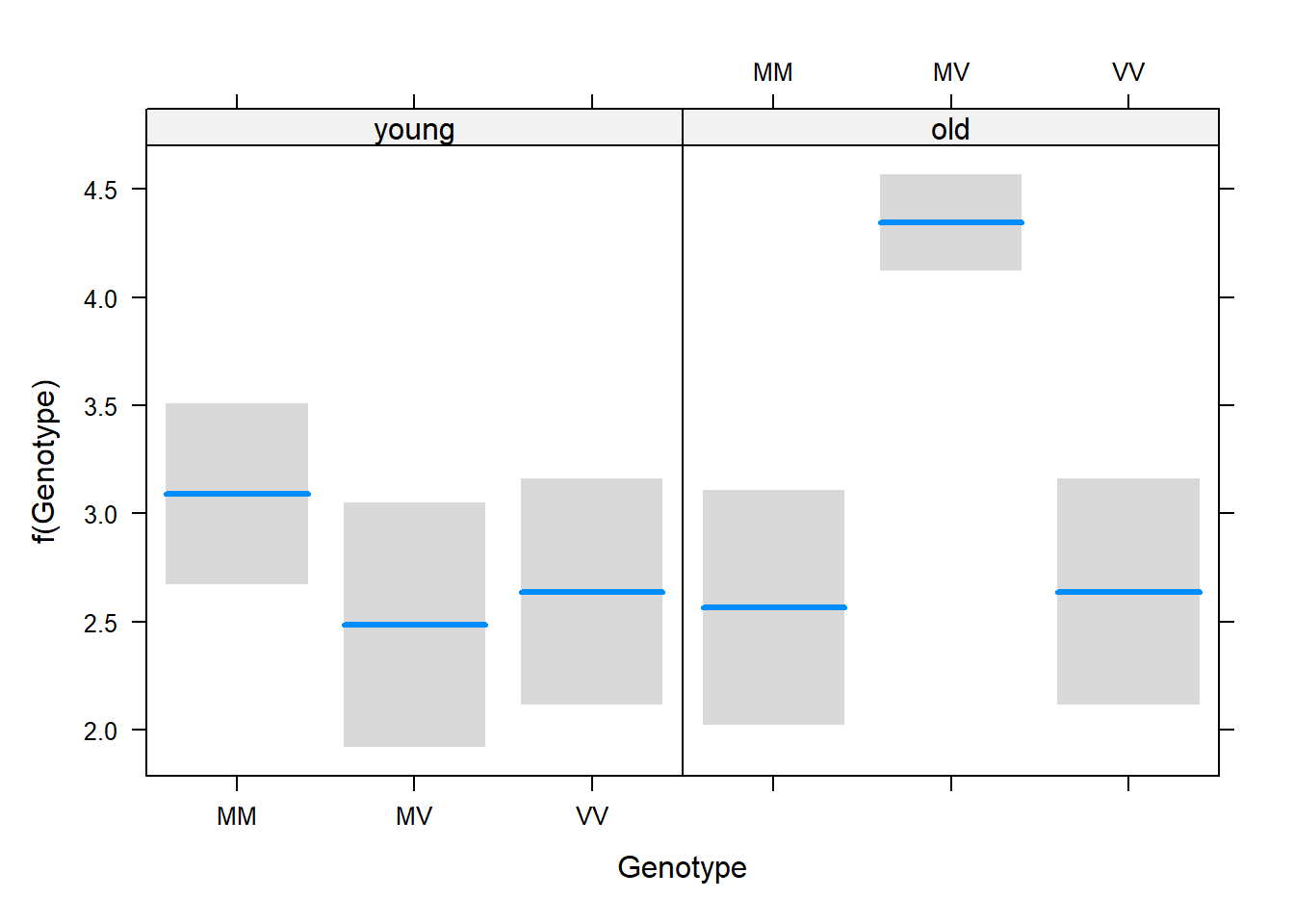
Repeat the model fitting but include the interaction term as well. Visualize the fit of the model to the data. Notice how this “full” model really is full – it fits the frequencies exactly.
💡 Click here to view a solution
# Repeat the model fitting but include the interaction term as wellz2 <-glm(Freq ~ Genotype * Cohort, data = kuru2, family =poisson(link ="log"))# Visualize the fit of the model to the datavisreg(z2, xvar ="Genotype", by ="Cohort")
Test whether the relative frequencies of the three genotypes differs between the two age groups (i.e., whether there is a significant interaction between age and genotype).
💡 Click here to view a solution
# Test whether the relative frequencies of the three genotypes differs between the two age groupsanova(z2, test ="Chisq")