Create a good header section and table of contents
Save the script file with an informative name
set your working directory
Aim to make the script a future reference for doing things in R!
3 Introduction
In this lab we will use R to fit linear models to data to review basic principles of linear model fitting and implementation. Linear models for fixed effects are implemented in the R command lm(). This method is not suitable for models that contain random effects. We’ll start with linear regression because this is the most familiar type of linear model.
4 Linear Regression
The data we will be using are from Whitman et al. (2004 Nature 428: 175-178), who noticed that the amount of black pigmentation on the noses of male lions increases as they get older. They used data on the proportion of black on the noses of 32 male lions of known age (years) in Tanzania. We will use fit a linear model to these data to predict a lion’s age from the proportion of black in his nose. The data are in the file lions.csv.
4.1 Read and examine the data
Let’s start by reading the data from the file and examining it.
# Load librarieslibrary(visreg, warn.conflicts =FALSE)library(ggplot2, warn.conflicts =FALSE)# Read and examine the datax <-read.csv("data/lions.csv", stringsAsFactors =FALSE)# View first few lines of datahead(x)
age black
1 1.1 0.21
2 1.5 0.14
3 1.9 0.11
4 2.2 0.13
5 2.6 0.12
6 3.2 0.13
# Inspect data structurestr(x)
'data.frame': 32 obs. of 2 variables:
$ age : num 1.1 1.5 1.9 2.2 2.6 3.2 3.2 2.9 2.4 2.1 ...
$ black: num 0.21 0.14 0.11 0.13 0.12 0.13 0.12 0.18 0.23 0.22 ...
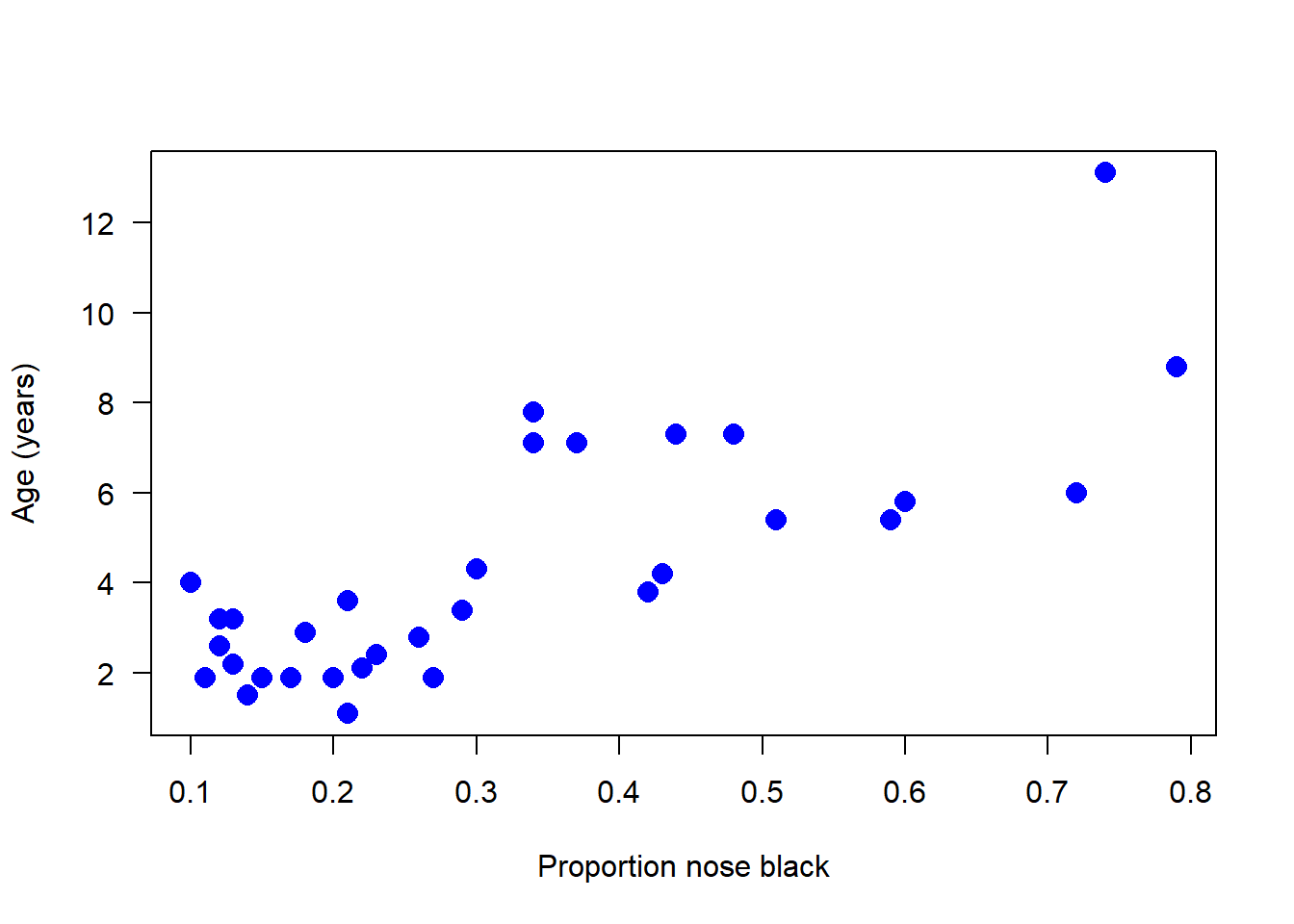
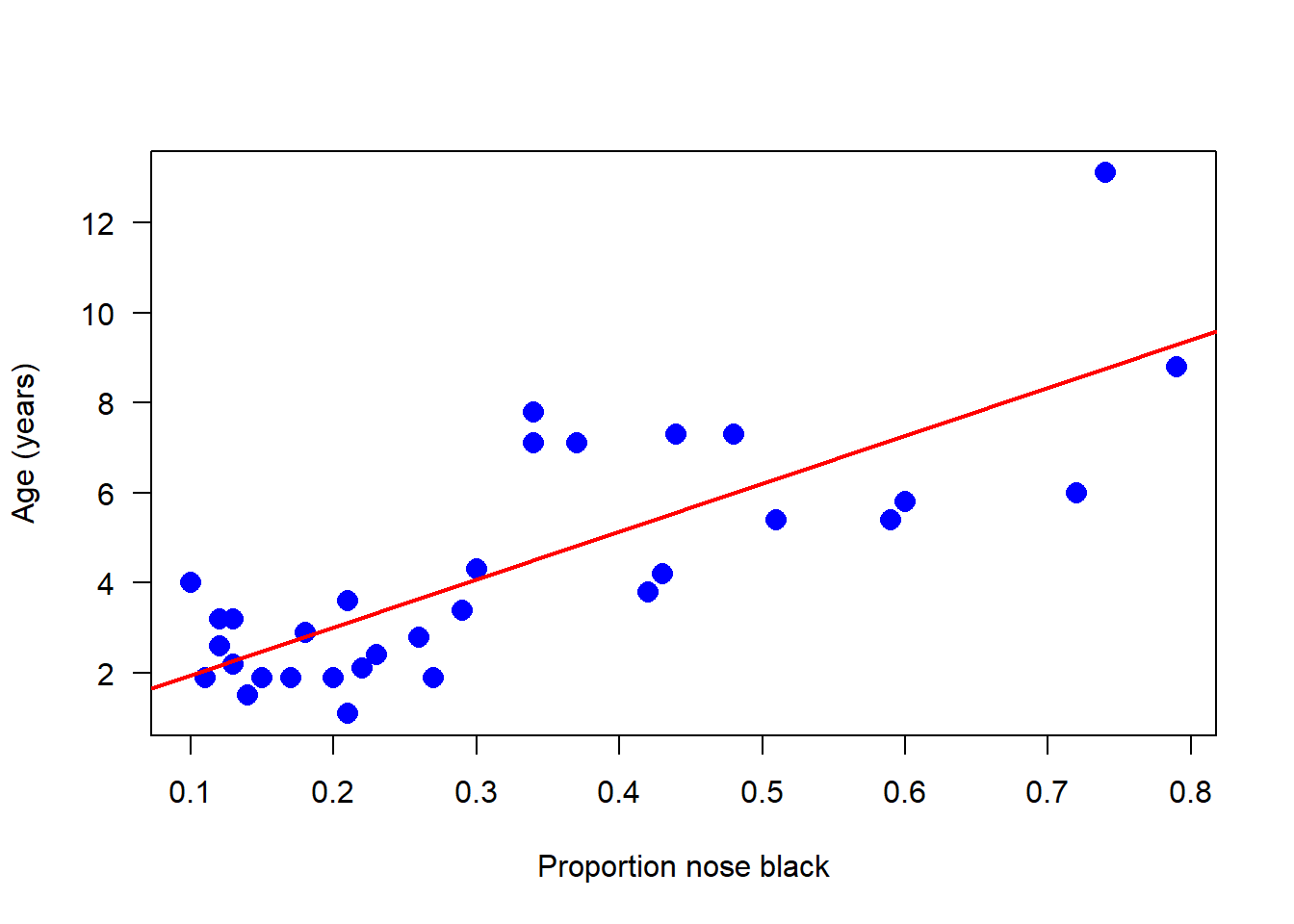
Great - this all looks good! Let’s create a scatter plot of the data. We have to choose the response and explanatory variables with care - we want to predict age from the proportion black in the nose:
# Scatter plotplot(age ~ black, data = x, pch =16, las =1, col ="blue", cex =1.5,xlab ="Proportion nose black", ylab ="Age (years)")
4.2 Fit a linear model
Now we have to fit a linear model to the lion data. We will store the output in an lm() object:
# Fit linear modelm1 <-lm(age ~ black, data = x)
We can examine the output from the lm() command using the summary() command:
# Summary of linear modelsummary(m1)
Call:
lm(formula = age ~ black, data = x)
Residuals:
Min 1Q Median 3Q Max
-2.5449 -1.1117 -0.5285 0.9635 4.3421
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.8790 0.5688 1.545 0.133
black 10.6471 1.5095 7.053 7.68e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.669 on 30 degrees of freedom
Multiple R-squared: 0.6238, Adjusted R-squared: 0.6113
F-statistic: 49.75 on 1 and 30 DF, p-value: 7.677e-08
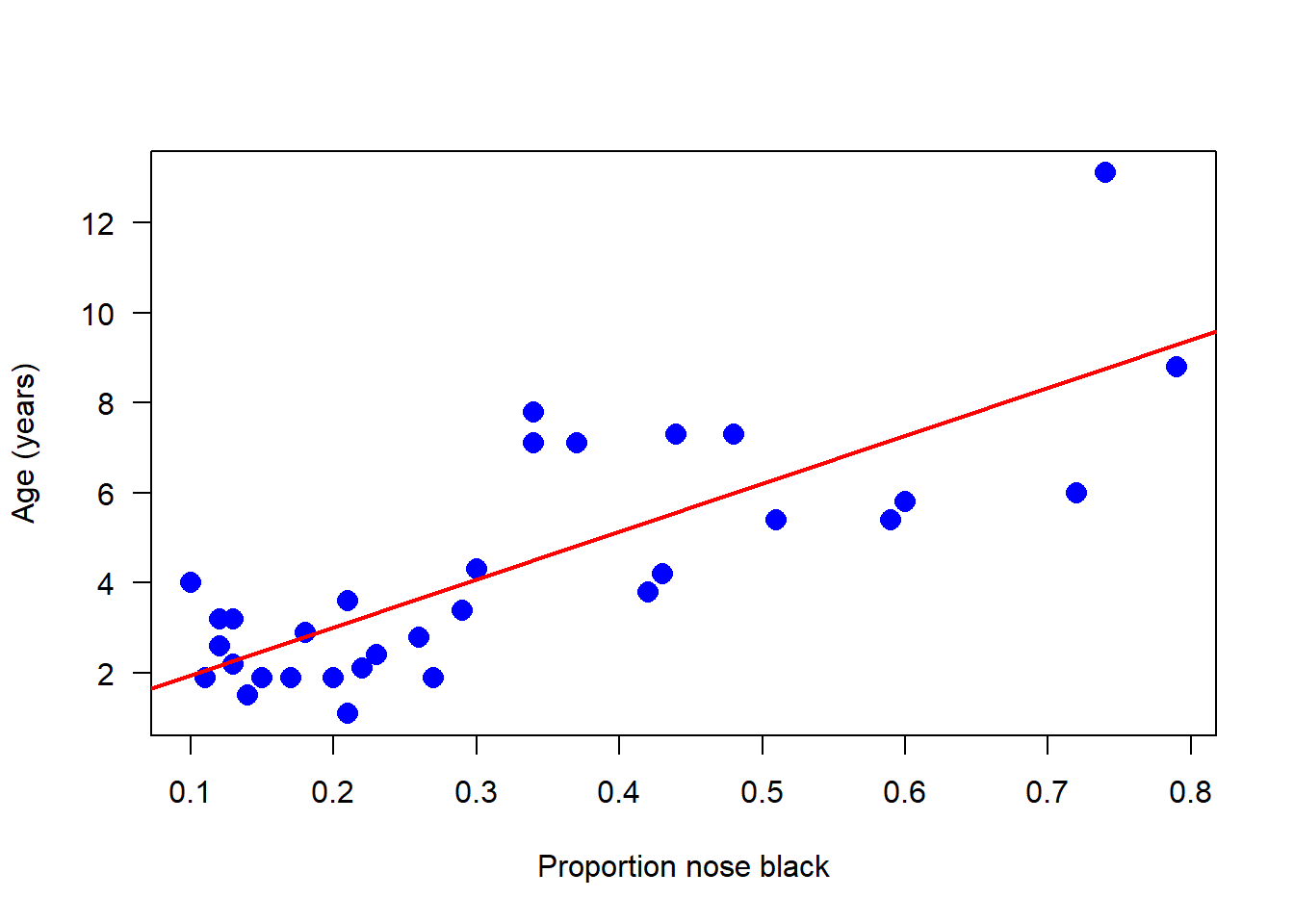
It seems as if there is something going on here at first glance. Let’s use this model to add the best-fit line to the scatter plot. Does the relationship appear linear? From the scatter plot, visually check for any serious problems such as outliers or changes in the variance of residuals:
# Scatter plot with regression lineplot(age ~ black, data = x, pch =16, las =1, col ="blue", cex =1.5,xlab ="Proportion nose black", ylab ="Age (years)")# Add regression lineabline(m1, col ="red", lwd =2)
The relationship appears to be linear, but there is a lot of scatter around the line. Using the same fitted model object (m1) we can obtain the estimates for the coefficients, slope and intercept, and standard errors.
# "(Intercept)" refers to intercept, "black" to slopesummary(m1)
Call:
lm(formula = age ~ black, data = x)
Residuals:
Min 1Q Median 3Q Max
-2.5449 -1.1117 -0.5285 0.9635 4.3421
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.8790 0.5688 1.545 0.133
black 10.6471 1.5095 7.053 7.68e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.669 on 30 degrees of freedom
Multiple R-squared: 0.6238, Adjusted R-squared: 0.6113
F-statistic: 49.75 on 1 and 30 DF, p-value: 7.677e-08
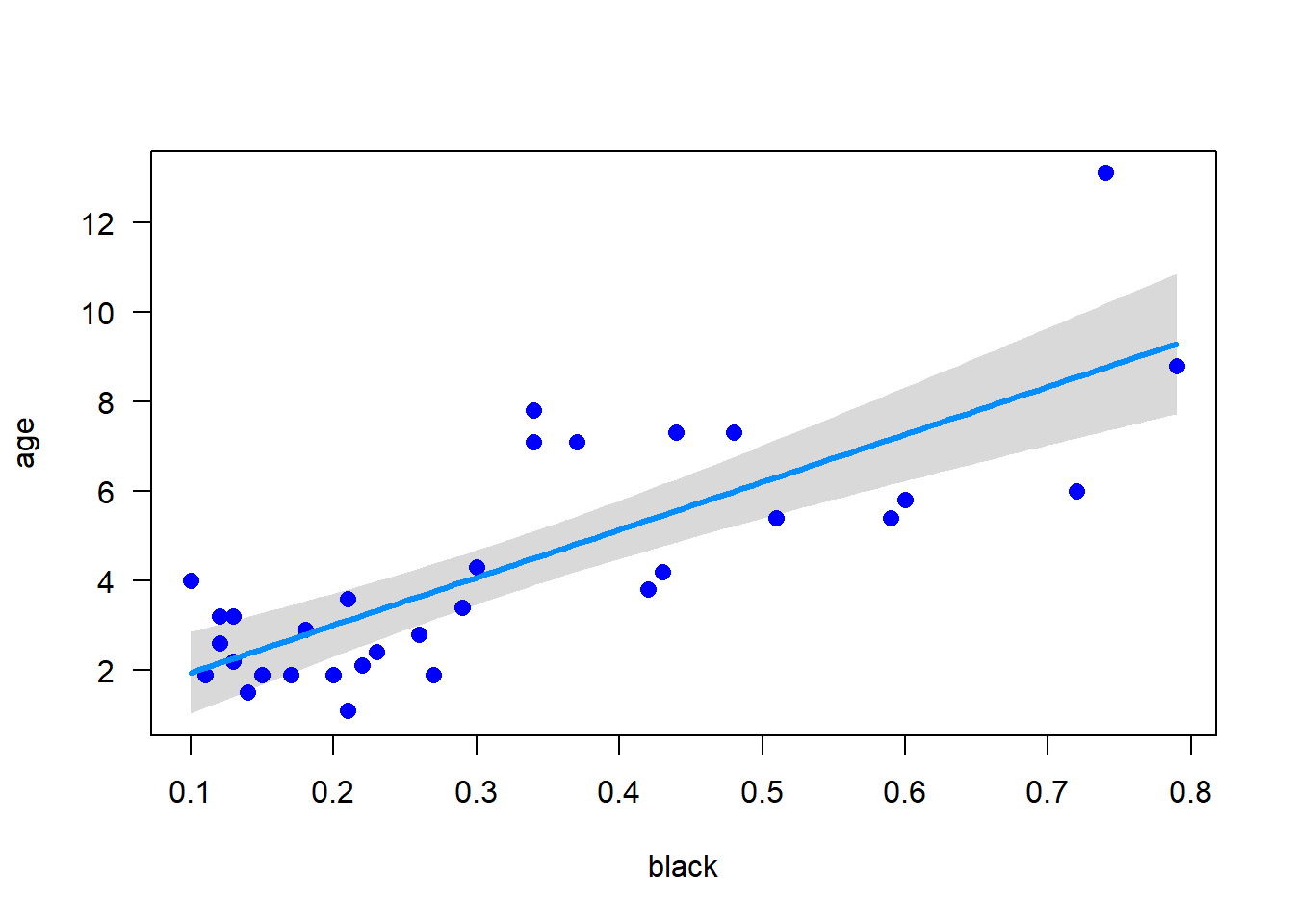
visreg(m1, points.par =list(pch =16, cex =1.2, col ="blue"))
What is the R2 value for the model fit? What does this mean?
# R2 valuesummary(m1)$r.squared
[1] 0.623827
The R2 value is 0.62, which means that 62% of the variation in age is explained by the proportion of black in the nose. This is a fairly high value for a biological system. Let’s now calculate the 95% confidence intervals for the slope and intercept:
# 95% confidence intervals for slope and interceptconfint(m1)
2.5 % 97.5 %
(Intercept) -0.2826733 2.040686
black 7.5643082 13.729931
We can test the fit of the model to the data with an ANOVA table:
# ANOVA tableanova(m1)
Analysis of Variance Table
Response: age
Df Sum Sq Mean Sq F value Pr(>F)
black 1 138.544 138.544 49.751 7.677e-08 ***
Residuals 30 83.543 2.785
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The ANOVA table shows that the model is highly significant (p < 0.001). The F-statistic is 48.75, which is the ratio of the mean square for the model to the mean square for the residuals. The mean square for the model is the sum of squares for the model divided by the degrees of freedom for the model. The mean square for the residuals is the sum of squares for the residuals divided by the degrees of freedom for the residuals. The degrees of freedom for the model is the number of parameters estimated (1) and the degrees of freedom for the residuals is the number of data points minus the number of parameters estimated (30). The p-value for the F-statistic is the probability of getting an F-statistic as large as 49.75 if the null hypothesis is true. The null hypothesis is that the model is not significant, i.e., that the slope is zero. The p-value is very small, so we can reject the null hypothesis and conclude that the model is significant.
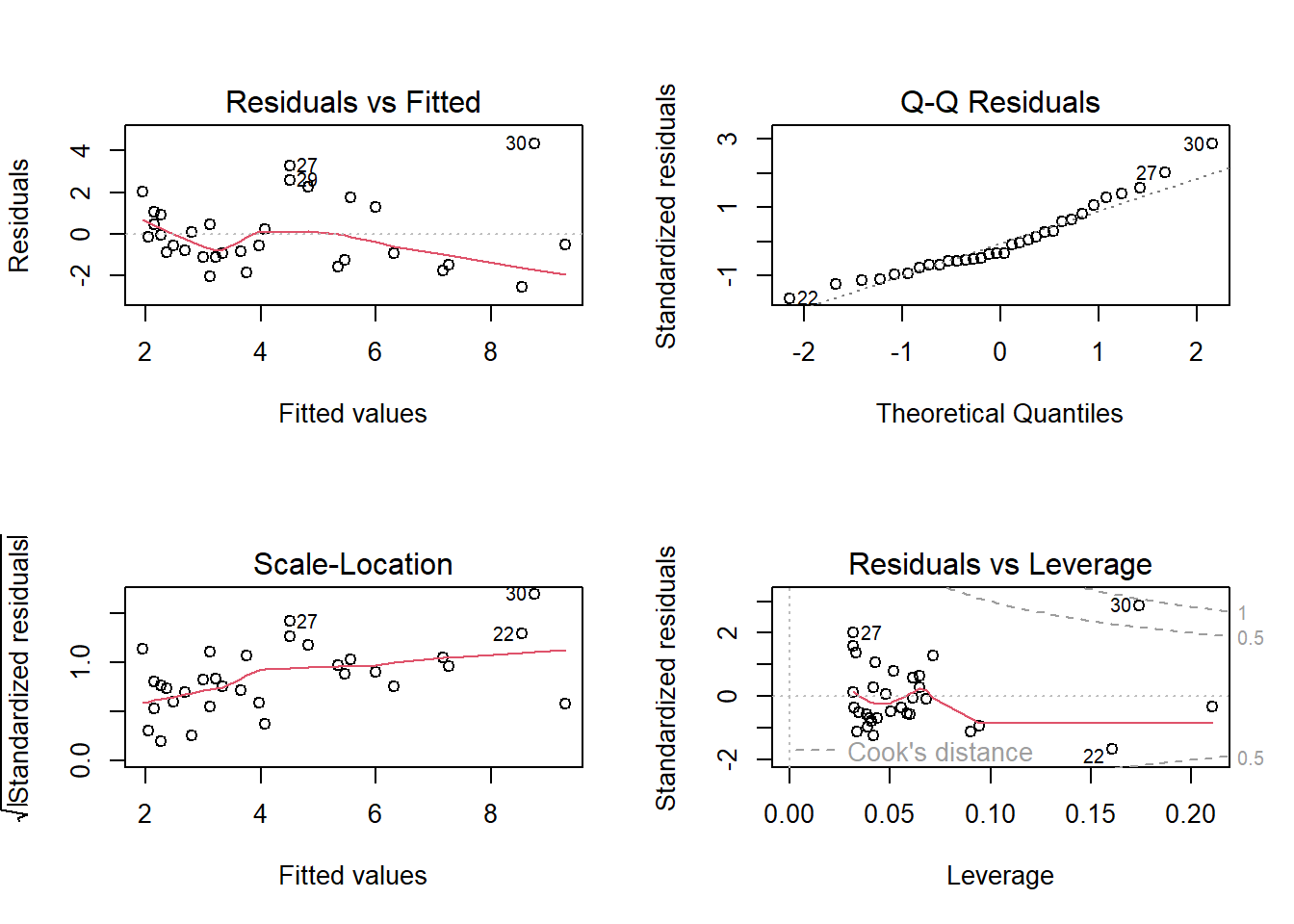
We can apply the plot() command to the lm() object created in (1) to diagnose violations of assumptions:
# Plot all residuals in one outputpar(mfrow =c(2, 2))plot(m1)
Recall the assumptions of linear models. Do the data conform to the assumptions? Are there any potential concerns? What options would be available to you to overcome any potential problems with meeting the assumptions? Most of the plots will be self-explanatory, except perhaps the last one. “Leverage” calculates the influence that each data point has on the estimated parameters. For example if the slope changes a great deal when a point is removed, that point is said to have high leverage. “Cook’s distance” measures the effect of each data point on the predicted values for all the other data points. A value greater than 1 is said to be worrisome. Points with high leverage don’t necessarily have high Cook’s distance, and vice versa.
One of the data points (the oldest lion) has rather high leverage. To see the effect this has on the results, let’s refit the data leaving this point out:
# Fit linear model without outlierm2 <-lm(age ~ black, data = x[-31, ])# Summary of linear modelsummary(m1)
Call:
lm(formula = age ~ black, data = x)
Residuals:
Min 1Q Median 3Q Max
-2.5449 -1.1117 -0.5285 0.9635 4.3421
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.8790 0.5688 1.545 0.133
black 10.6471 1.5095 7.053 7.68e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.669 on 30 degrees of freedom
Multiple R-squared: 0.6238, Adjusted R-squared: 0.6113
F-statistic: 49.75 on 1 and 30 DF, p-value: 7.677e-08
summary(m2)
Call:
lm(formula = age ~ black, data = x[-31, ])
Residuals:
Min 1Q Median 3Q Max
-2.6589 -1.1076 -0.5546 1.0176 4.2234
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.8218 0.6036 1.362 0.184
black 10.8847 1.6974 6.413 5.17e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.694 on 29 degrees of freedom
Multiple R-squared: 0.5864, Adjusted R-squared: 0.5722
F-statistic: 41.12 on 1 and 29 DF, p-value: 5.169e-07
Did this change the regression line substantially?
💡 Click here to view a solution
The variance of the residuals for black in the nose tends to rise with increasing age but the trend is not severe. The residuals might not be quite normal, but they are not badly skewed so we are probably OK.
** 0.61
*** It is even easier to see with these plots how the variance of the residuals tends to increase at higher fitted values. A transformation of one or both of the variables is usually the first course of action. R also has a toolkit for robust regression, which as the name suggests is more robust to violations of standard assumptions.
4.3 Prediction
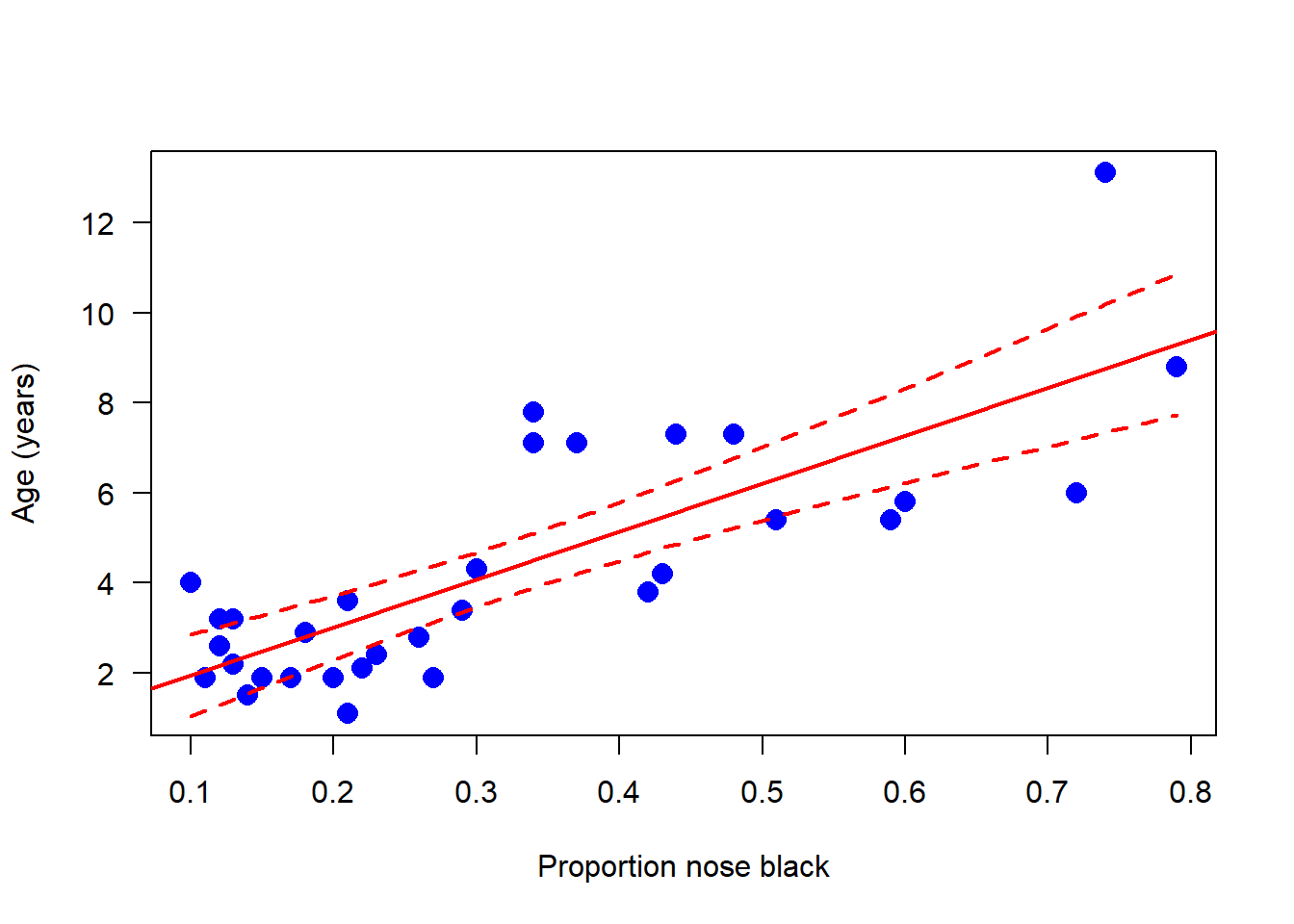
We can also use linear models to make predictions. For example, we can predict the age of a lion with a proportion black in the nose of 0.5. Let’s sisplay the data once again in a scatter plot and add the regression line:
# Scatter plot with regression lineplot(age ~ black, data = x, pch =16, las =1, col ="blue", cex =1.5,xlab ="Proportion nose black", ylab ="Age (years)")# Add regression lineabline(m1, col ="red", lwd =2)
We will also add confidence bands to the scatter plot. These are confidence limits for the prediction of mean of lion age at each value of the explanatory variable. You can think of these as putting bounds on the most plausible values for the “true” or population regression line. Note the spread between the upper and lower limits and how this changes across the range of values for age. Let’s add prediction intervals to the scatter plot. These are confidence limits for the prediction of new individual lion ages at each value of the explanatory variable:
# Fit a linear modelm1 <-lm(age ~ black, data = x)# Scatter plotplot(age ~ black, data = x, pch =16, las =1, col ="blue", cex =1.5,xlab ="Proportion nose black", ylab ="Age (years)")# Add regression lineabline(m1, col ="red", lwd =2)# Add confidence bandsx_range <-range(x$black)x_seq <-seq(from = x_range[1], to = x_range[2], length.out =100)conf_int <-predict(m1, newdata =data.frame(black = x_seq), interval ="confidence")# Plotting the upper and lower confidence bandslines(x_seq, conf_int[, "lwr"], col ="red", lwd =2, lty =2)lines(x_seq, conf_int[, "upr"], col ="red", lwd =2, lty =2)
Whereas confidence bands address questions like “what is the mean age of lions whose proportion black in the nose is 0.5 ?”, prediction intervals address questions like “what is the age of that new lion over there, which has a proportion black in the nose of 0.5 ?” Examine the confidence bands and prediction intervals. Is the prediction of mean lion age from black in the nose relatively precise? Is prediction of individual lion age relatively precise? Could this relationship be used in the field to age lions?
5 Categorical Explanatory Variables
Our second example fits a linear model with a categorical explanatory variable. The data are from an experiment by Wright and Czeisler (2002. Science 297: 571) that re-examined a previous claim that light behind the knees could reset the circadian rhythm of an individual the same way as light to the eyes. One of three light treatments was randomly assigned to 22 subjects (a three-hour episode of bright lights to the eyes, to the knees, or to neither). Effects were measured two days later as the magnitude of phase shift in each subject’s daily cycle of melatonin production, measured in hours. A negative measurement indicates a delay in melatonin production, which is the predicted effect of light treatment. The data are in the file knees.csv.
5.1 Read and Examine the Data
We begin by loading the data to understand its structure and prepare it for analysis. We will use the read.csv() function to read the data into R. The stringsAsFactors = FALSE argument tells R not to convert character variables to factors. This is important because we want to treat the treatment variable as a factor, not a numeric variable.
library(visreg, warn.conflicts=FALSE)library(ggplot2, warn.conflicts=FALSE)library(emmeans, warn.conflicts=FALSE)# Read the datax <-read.csv("data/knees.csv", stringsAsFactors =FALSE)# View first few lines to check correctnesshead(x)
treatment shift
1 control 0.20
2 control 0.53
3 control -0.68
4 control -0.37
5 control -0.64
6 control 0.36
# Ensure 'treatment' is a factor for analysisis.factor(x$treatment)
[1] FALSE
x$treatment <-factor(x$treatment)
5.2 Visualise the Data
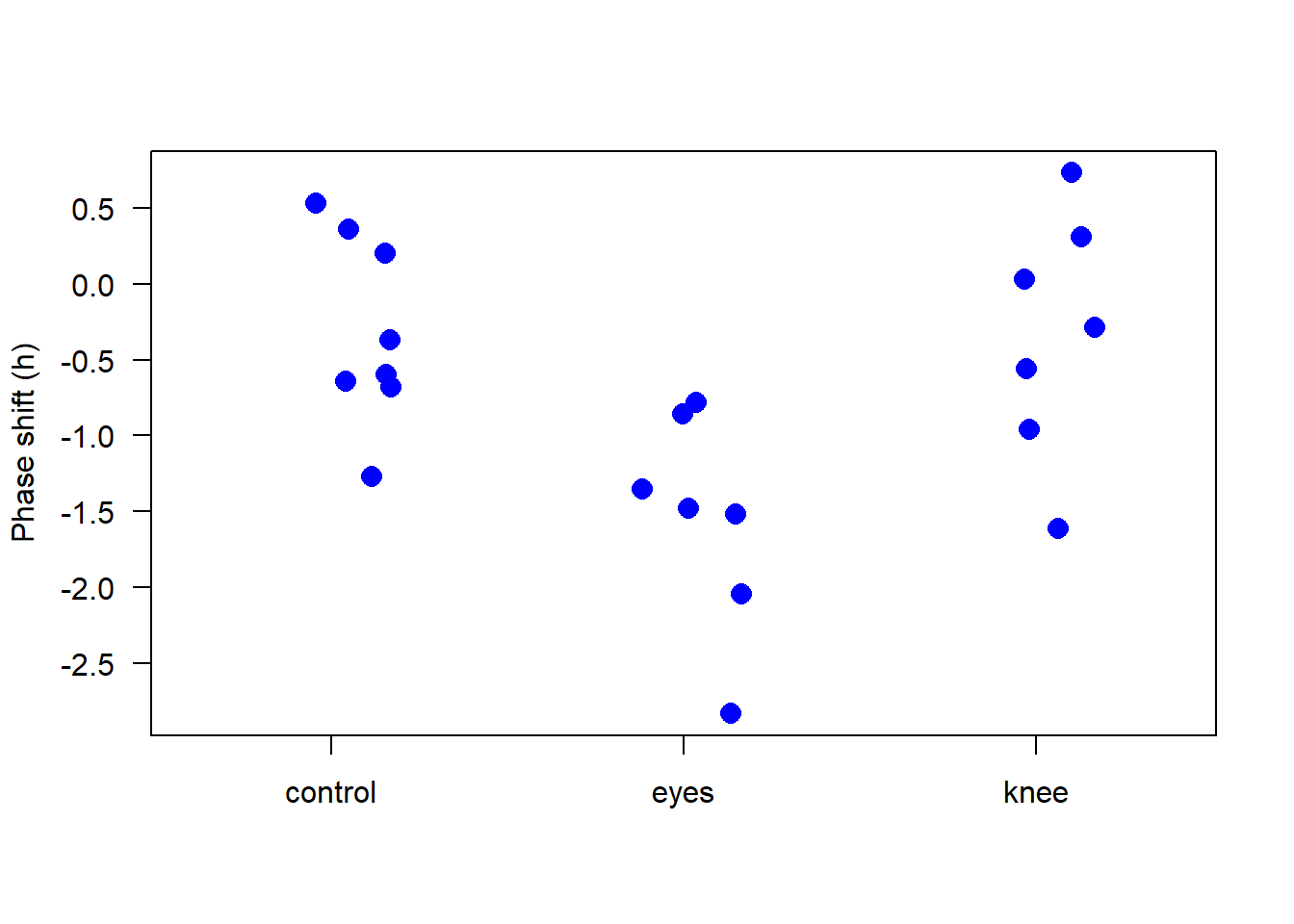
We will use a stripchart to visualize the data. This is a scatter plot of the response variable (phase shift) against the explanatory variable (treatment), with the points stacked along the x-axis to avoid overlap. We will use the stripchart() function to create the plot:
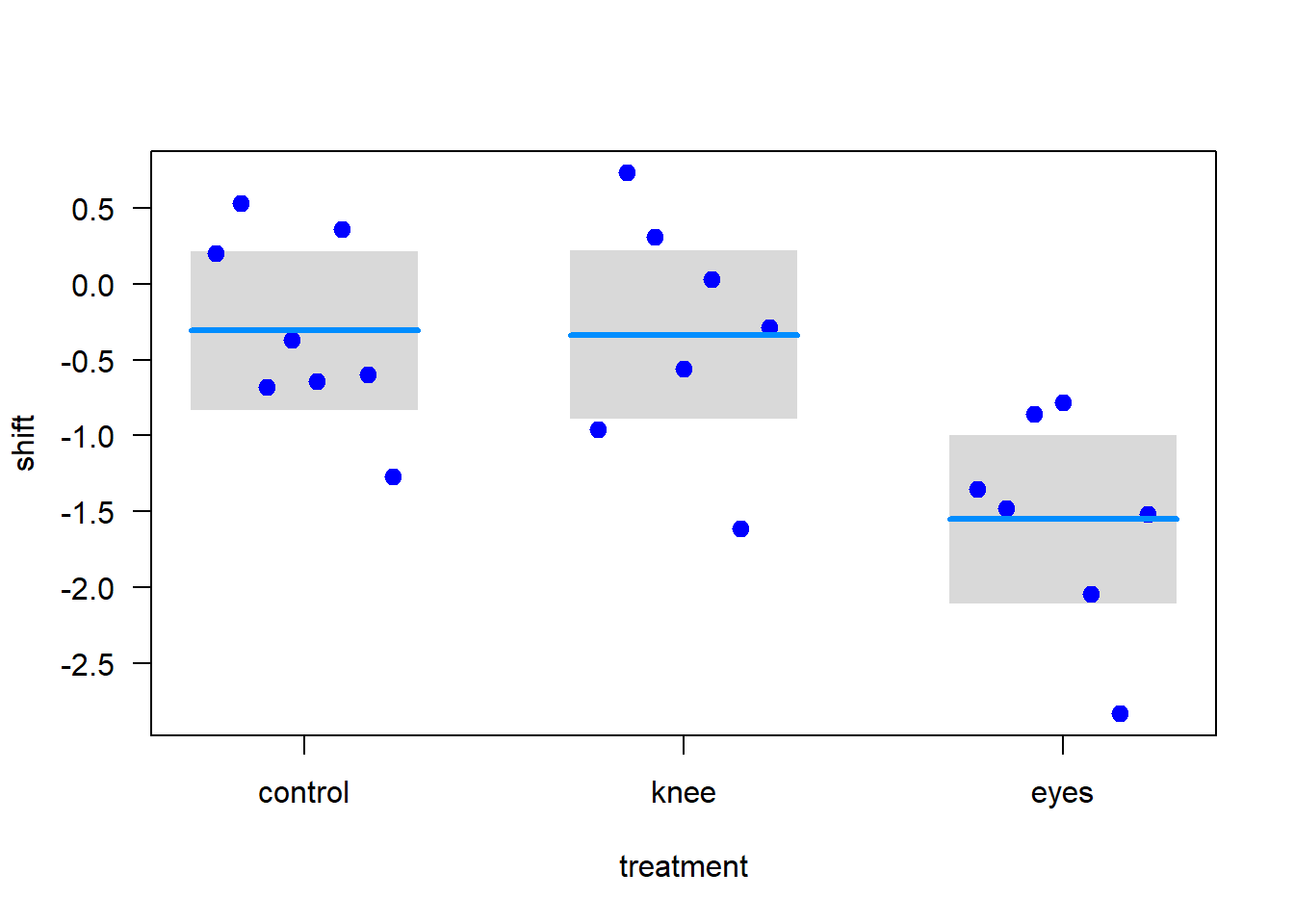
# Initial plot to visualize phase shiftsstripchart(shift ~ treatment, data=x, vertical =TRUE, method ="jitter", jitter =0.2, pch =16, las =1, cex =1.5, col ="blue",ylab ="Phase shift (h)")
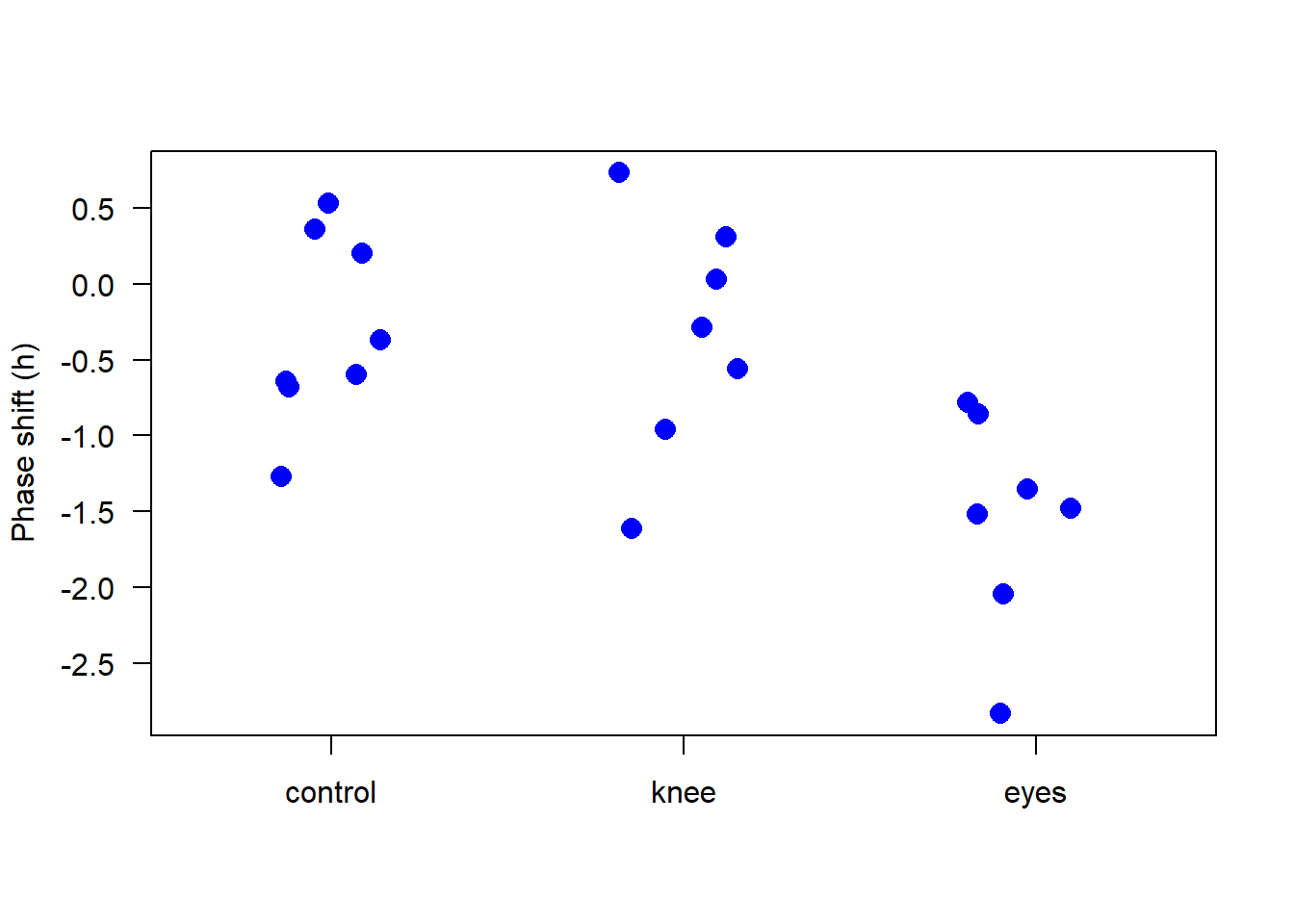
Next, we explore the treatment factor levels, reordering them for convenience in analysis. This is crucial for interpreting the model coefficients correctly later.
# Examine and reorder factor levelslevels(x$treatment)
# Replot data to see the effect of reorderingstripchart(shift ~ treatment, data=x, vertical =TRUE, method ="jitter", jitter =0.2, pch =16, las =1, cex =1.5, col ="blue",ylab ="Phase shift (h)")
5.3 Fit a Linear Model
Our goal here is to fit a linear model to analyse the effect of different light treatments on circadian rhythms, measured by phase shifts in melatonin production.
# Fit linear modelz <-lm(shift ~ treatment, data=x)# Visual representation of model fitvisreg(z, whitespace =0.4, points.par =list(cex =1.2, col ="blue"))
5.4 Interpret the Model
We can now interpret the model using the summary() function. The model summary shows the estimated coefficients for each treatment level, along with their standard errors, t-values, and p-values. The coefficients represent the average effect for the control group and the difference in effect for the other groups compared to control. The p-values are not generally valid for a posteriori comparisons. They might be valid for planned comparisons, but for multiple group comparisons, a Tukey test or similar is more appropriate.
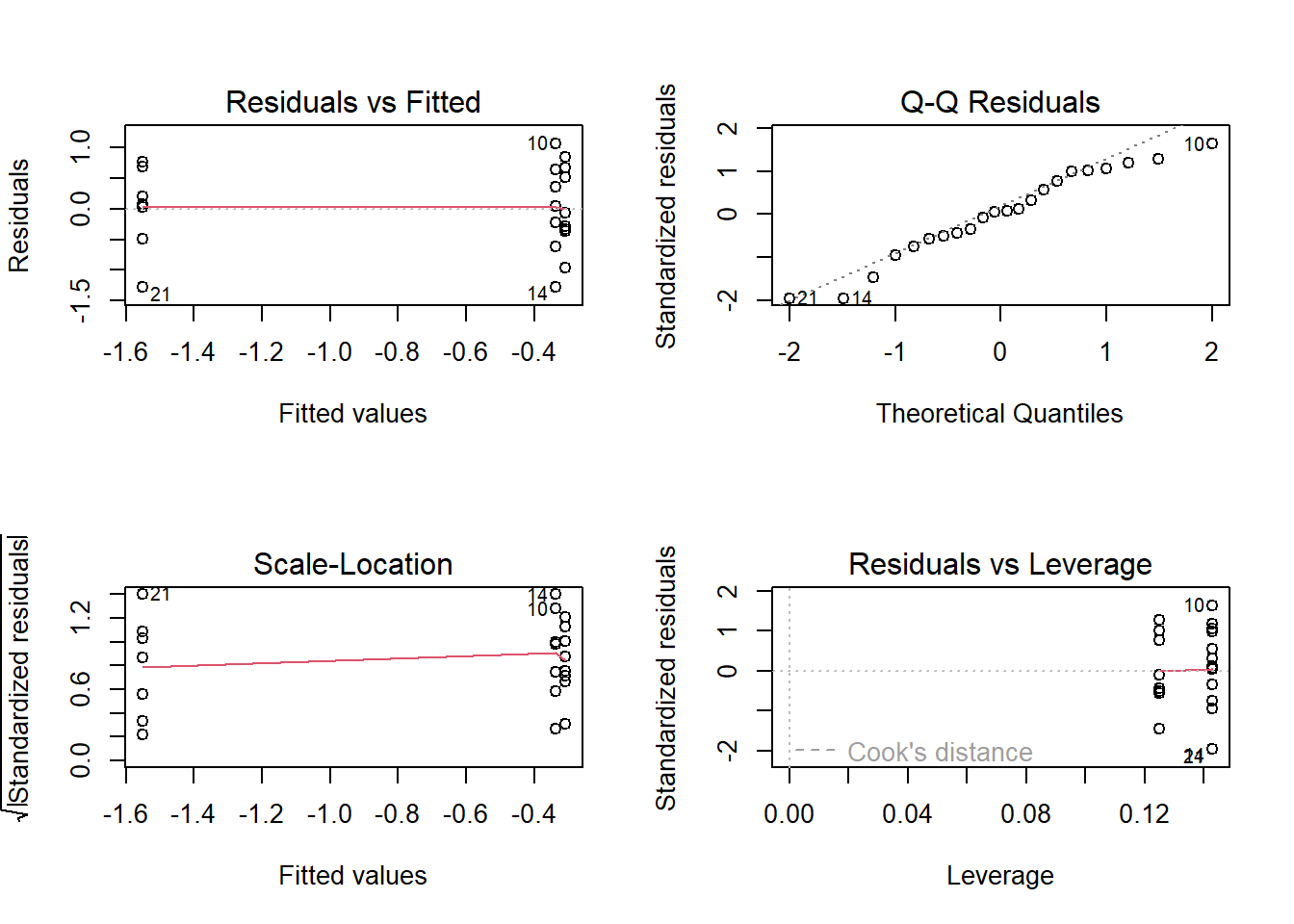
# Check for model assumptions and potential issuespar(mfrow =c(2,2))plot(z)
par(mfrow =c(1,1))# Understand the model's internal representationmodel.matrix(z)
Note: In the model matrix, one of the columns is dropped to avoid redundancy. This is typically the first level of the categorical variable by default.
Interpreting Coefficients: - The coefficients represent the average effect for the control group and the difference in effect for the other groups compared to control.
About P-values: - P-values in this context are not generally valid for a posteriori comparisons. They might be valid for planned comparisons, but for multiple group comparisons, a Tukey test or similar is more appropriate.
6 Activity
In this activity you are going to use the fruitflies.csv data. The data relate to sexual activity and the lifespan of male fruit flies. The experiment placed male fruit flies with varying numbers of previously-mated or virgin females to investigate whether mating activity affects male lifespan. You are going to model this data. The linear model will have longevity as the response variable, and two explanatory variables: treatment (categorical) and thorax length (numerical; representing body size). The goal will be to compare differences in fly longevity among treatment groups, correcting for differences in thorax length. Correcting for thorax length will possibly improve the estimates of treatment effect. The method is also known as analysis of covariance, or ANCOVA. Your task is to:
Read the data from the file.
View the first few lines of data to make sure it was read correctly.
Determine whether the categorical variable “treatment” is a factor. If not a factor, convert treatment to a factor. This will be convenient when we fit the linear model.
Use the levels() function on the factor variable “treatment” to see how R has ordered the different treatment groups (should be alphabetically).
Change the order of the categories so that a sensible control group is first in the order of categories. Arrange the order of the remaining categories as you see fit.
Create a scatter plot, with longevity as the response variable and body size (thorax length) as the explanatory variable. Use a single plot with different symbols (and colors too, if you like) for different treatment groups. Or make a multipanel plot using the ggplot2 package
Fit a linear model to the fly data, including both body size (thorax length) and treatment as explanatory variables. Place thorax length before treatment in the model formula. Leave out the interaction term for now – we’ll assume for now that there is no interaction between the explanatory variables thorax and treatment.
Use plot() to check whether the assumptions of linear models are met in this case. Are there any potential concerns? If you have done the analysis correctly, you will see that the variance of the residuals is not constant, but increases with increasing fitted values. This violates the linear model assumption of equal variance of residuals.
Attempt to fix the problem identified in step (8) using a log-transformation of the response variable. Refit the model and reapply the graphical diagnostic tools to check assumptions. Any improvements? (To my eye the situation is improved but the issue has not gone away entirely.) Let’s continue anyway with the log-transformed analysis.
Visualise the fit of the model to the data using the visreg package. Try two different possibilities. In the first, plot the fit of the response variable to thorax length separately for each treatment group. In the second, plot the fit of the data to treatment, conditioning on the value of the covariate (thorax length).
Obtain the parameter estimates and standard errors for the fitted model. Interpret the parameter estimates. What do they represent*? Which treatment group differs most from the control group?
Obtain 95% confidence intervals for the treatment and slope parameters.
Test overall treatment effects with an ANOVA table. Interpret each significance test – what exactly is being tested?
Refit the model to the data but this time reverse the order in which you entered the two explanatory variables in the model. Test the treatment effects with an ANOVA table. Why isn’t the table identical to the one from your analysis in (7)**?
Our analysis so far has assumed that the regression slopes for different treatment groups are the same. Is this a valid assumption? We have the opportunity to investigate just how different the estimated slopes really are. To do this, fit a new linear model to the data, but this time include an interaction term between the explanatory variables.
The parameters will be more complicated to interpret in the model including an interaction term, so lets skip this step. Instead, go right to the ANOVA table to test the interaction term using the new model fit. Interpret the result. Does it mean that the interaction term really is zero?
Another way to help assess whether the assumption of no interaction is a sensible one for these data is to determine whether the fit of the model is “better” when an interaction term is present or not, and by how much. We will learn new methods later in the course to determine this, but in the meantime a simple measure of model fit can be obtained using the adjusted \(R^2\) value. The ordinary \(R^2\) measures the fraction of the total variation in the response variable that is “explained” by the explanatory variables.
This, however, cannot be compared between models that differ in the number of parameters because fitting more parameters always results in a larger \(R^2\), even if the added variables are just made-up random numbers. To compare the fit of models having different parameters, use the adjusted \(R^2\) value instead, which takes account of the number of parameters being fitted. Use the summary() command on each of two fitted models, one with and the other without an interaction term, and compare their adjusted \(R^2\) values. Are they much different? If not, then maybe it is OK to assume that any interaction term is likely small and can be left out.
*In a linear model with a factor and a continuous covariate, and no interaction term, the coefficient for the covariate is the common regression slope. The “intercept” coefficient represents the y-intercept of the first category (first level in the order of levels) of the treatment variable. Remaining coefficients represent the difference in intercept between that of each treatment category and the first category.
**R fits model terms sequentially when testing. Change the order of the terms in the formula for the linear model and the results might change.
💡 Click here to view a solution
# Load necessary librarieslibrary(ggplot2)library(visreg)# 1. Read fruit fly data from a CSV filefly <-read.csv("data/fruitflies.csv", stringsAsFactors =FALSE)# 2. Display the first few rows of the datasethead(fly)# 3. Check if 'treatment' column is a factor and convert it if notis.factor(fly$treatment)fly$treatment <-factor(fly$treatment)# 4. Display the levels of the 'treatment' factorlevels(fly$treatment)# 5. Reorder the levels of the 'treatment' factor, putting controls firstfly$treatment <-factor(fly$treatment, levels =c("no females added", "1 virgin female", "1 pregnant female", "8 virgin females","8 pregnant females"))# 6. Create a multipanel scatter plot with linear regression lines# Thorax size vs. Longevity for different treatmentsggplot(fly, aes(thorax.mm, longevity.days)) +geom_point(col ="blue", size =2) +geom_smooth(method = lm, size =I(1), se =FALSE, col ="firebrick") +xlab("Thorax (mm)") +ylab("Longevity (days)") +facet_wrap(~ treatment, ncol =2) +theme_classic()# 7. Fit a linear model with longevity as response and thorax size and treatment as predictorsz <-lm(longevity.days ~ thorax.mm + treatment, data = fly)# 8. Plot diagnostic plots for the linear model 'z'par(mfrow =c(2,2))plot(z)par(mfrow =c(1,1))# 9. Transform longevity to logarithmic scale and fit a linear modelfly$log.longevity <-log(fly$longevity)z <-lm(log.longevity ~ thorax.mm + treatment, data = fly)# Plot diagnostic plots for the log-transformed linear modelpar(mfrow =c(2,2))plot(z)par(mfrow =c(1,1))# 10. Visualize regression models using visreg package# Conditional plotvisreg(z, xvar ="thorax.mm", type ="conditional", points.par =list(cex =1.1, col ="blue"))# Separate plots in separate panelsvisreg(z, xvar ="thorax.mm", by ="treatment", whitespace =0.4, points.par =list(cex =1.1, col ="blue"))# Separate plots overlaidvisreg(z, xvar ="thorax.mm", by ="treatment", overlay =TRUE, band =FALSE, points.par =list(cex =1.1), legend =FALSE)# 11. Display the summary of the linear model 'z'summary(z)# 12. Display the confidence intervals for model parametersconfint(z)# 13. Perform an ANOVA (analysis of variance) on the linear model 'z'anova(z)# 14. Fit a new linear model 'z1' with a different order of predictors and perform ANOVAz1 <-lm(log.longevity ~ treatment + thorax.mm, data = fly)anova(z1)# 15. Fit a linear model 'z' with interaction between thorax size and treatmentz <-lm(log.longevity ~ thorax.mm * treatment, data = fly)# 16. Perform an ANOVA on the linear model with interaction termsanova(z)